

0. 개요
영상 업로드, 트랜스코딩, 스트리밍 가능한 OTT 프로젝트를 진행하면서 영상 처리에 사용되는 개념들을 처음 접했습니다. 익숙하지 않았고 비슷한 개념들이 많았기 때문에 뭐가 뭔지 파악하는 것부터 난관이었습니다. 이번 글에서는 아키텍처나 세세한 설정, 개념이 아닌 영상 처리에 있어 필수적인 기본 개념들을 소개하는 느낌으로 정리해보았습니다.
트랜스코딩이나 영상 처리 개발 관련 개념을 빠르게 보고 싶으신 분은 '2-3 코덱과 컨테이너’ 부분부터 보시면 됩니다!
1. 동영상이란
동영상은 여러 이미지(영상)들과 오디오, 자막 등 부가 데이터의 조합입니다. 이렇게 생각하면 모호하게 느껴지니 이미지부터 하나씩 알아보고 이들을 조합해보겠습니다.
1-1. 프레임과 비트레이트
프레임
동영상에서는 사진을 빠르게 이어 붙여 사람에게 움직이는 것처럼 보이게 합니다. 우리 눈은 1초에 24장 이상의 그림이 바뀌면 움직이는 것으로 인식한다고 합니다.
학창 시절에 책 모서리에 그림을 그려놓고 빠르게 파바박 넘겼을 때 움직이는 것처럼 보였던 것과 같습니다.

이때, 한 장의 정지 영상을 프레임(Frame)이라고 하며, 영상 1초에 들어가는 프레임의 수를 프레임레이트(FPS, Frames Per Second)라고 합니다. 게임에서 네트워크가 느릴 때 fps를 보는데, 바로 이것입니다.
비트레이트
비트레이트는 1초당 사용하는 데이터의 양입니다. 단위는 bps(bits per second)를 사용하며, 영상에서는 주로 Kbps나 Mbps 단위가 쓰입니다. 영상 품질과 파일 크기를 결정하는 요소로, 비트레이트가 높을수록 빠른 것이 아니라 고품질이며 파일 용량이 큽니다.

비트레이트가 높을수록 영상을 표현하기 위한 데이터가 더 많이 필요합니다. 하지만, 그만큼 초당 전송해야 할 데이터의 양이 많아지기 때문에 네트워크 속도가 빨라야 합니다. 느린 네트워크 환경에서 높은 비트레이트의 영상을 재생하면 데이터를 충분히 받지 못하게 되어 버퍼링이 발생하게 됩니다.
1-2. 픽셀과 해상도
한 장의 이미지인 프레임은 다시 아주 작은 블럭들로 이루어져 있으며,이 블럭들을 픽셀(Pixel)이라고 합니다.

여기서 각 픽셀은 색을 나타내고, 한 프레임에 들어갈 수 있는 픽셀 수가 해상도입니다.
색을 저장하는 방법
저에겐 미술이 너무 어렵지만, 색을 나타내는 가장 직관적인 방식은 빛의 삼원색을 섞는 방식이라고 배웠던 기억이 있습니다. RGB를 얼마씩 섞느냐로 모든 색을 만들 수 있습니다. 각 색마다 1바이트씩 사용하며, 픽셀 1개당 3바이트를 차지합니다.

하지만, 픽셀 하나가 3byte를 차지하게 되므로 영상이 길어질수록 용량이 어마어마하게 늘어날 수 있습니다.
픽셀당 3바이트로 FHD 영상 1시간 용량을 계산해 보면 아래와 같습니다.
픽셀 수 : 1920 × 1080 ≈ 207만 픽셀
픽셀당 색 : 3 byte (RGB)
프레임 1장 : 207만 × 3 ≈ 6.2 MB
1초(30fps) : 6.2 MB × 30 ≈ 187 MB
1시간 : 187 MB × 3600 ≈ 660 GB이렇게 데이터를 있는 그대로 저장하는 것이 어렵기 때문에 영상에서는 RGB 대신 YUV와 크로마 서브샘플링 방식을 사용해서 크기를 줄입니다.
YUV와 크로마 서브샘플링
YUV는 밝기(Y)와 색차(U, V)를 분리해서 표현합니다.
사람 눈은 밝기 변화에는 민감하지만 색 변화에는 둔감합니다. 그래서 밝기는 꼼꼼히, 색은 대충 저장해도 사람은 차이를 거의 못 느낍니다. 문제는 RGB는 색과 밝기가 한 덩어리로 섞여 있어 ‘색만 골라서 줄이는 것’이 불가능하다는 점입니다.
그래서 먼저 YUV로 밝기와 색을 분리해 둡니다. 이렇게 떼어 놓으면 밝기(Y)는 그대로 두고 색(U, V)만 줄일 수 있습니다.
이때, ‘색 정보만 줄이는 기술’을 크로마 서브샘플링이라고 합니다. 주로 색상 정보를 2×2 픽셀당 1개씩만 저장하는 4:2:0 비율을 사용합니다.(해상도가 짝수인 이유)

2. 압축: 줄이고 표현하는 방법
압축의 본질은 ‘똑같거나, 사람이 못 느끼는 정보를 반복 저장하지 않는 것’입니다. 주로 용량을 줄이기 위한 목적으로 사용됩니다.
손실 압축과 무손실 압축이 있는데, 영상은 대부분 손실 압축이 사용됩니다. 화질을 약간 희생해서 용량을 많이 줄이기 위함입니다. 따라서 여러 번 반복되면 화질이 저하되어 화질구지가 될 수 있습니다.
2-1. 네 가지 압축 관점
| 구분 | 의미 | 예시 |
| 공간적 압축 | 한 프레임 안의 중복 제거 | 하늘처럼 비슷한 색 영역 압축 |
| 시간적 압축 | 프레임 사이의 중복 제거 | 이전 프레임과 달라진 부분만 저장 |
| 지각적 압축 | 사람이 잘 못 느끼는 정보 줄이기 | 색 정보 일부 줄이기, 미세한 디테일 제거 |
| 엔트로피 압축 | 남은 데이터를 더 짧은 코드로 표현 (표현 자체를 더 효율적으로 줄임) |
자주 나오는 값은 짧게, 드문 값은 길게 저장 |
사진과 다르게 영상은 시간이라는 축이 존재하기 때문에 시간적 압축을 통해 사진 묶음보다 훨씬 효율적으로 압축될 수 있습니다.
오디오 압축(AAC·MP3·Opus)도 똑같이 사람 귀의 약점을 이용합니다. 큰 소리에 묻혀 안 들리는 작은 소리, 사람이 못 듣는 주파수 대역을 버리는 방식입니다.(심리음향 압축). '압축 == 사람 지각의 약점을 이용한다.'는 원리는 영상의 색(눈)이든 오디오(귀)든 동일하게 적용됩니다.
2-2. I·P·B프레임과 GOP
영상에는 프레임이 여러 장 존재한다는 특성을 살려 프레임을 세 역할로 나누어 시간적 압축을 활용할 수 있습니다.
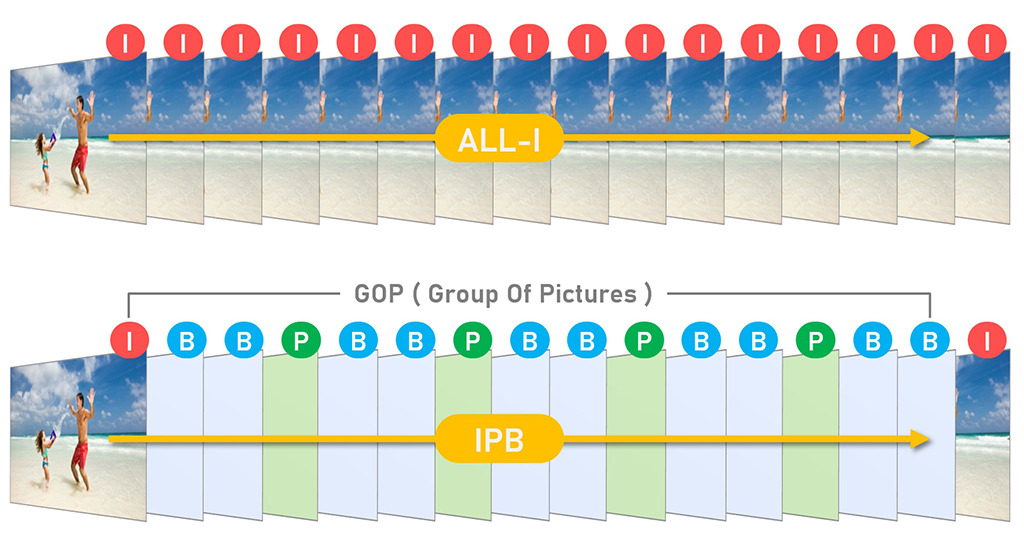
| 구분 | 의미 | 예시 |
| I 프레임 | - 다른 프레임을 참조하지 않고 자기 자신만으로 복원 가능한 프레임 - 용량은 크지만 탐색/재생 시작 기준이 됨 |
장면의 시작점, 탐색 기준점 |
| P 프레임 | 이전 프레임을 참고해서 변화한 부분 중심으로 저장하는 프레임 | 사람이 조금 움직인 부분만 저장 |
| B 프레임 | 이전 프레임과 이후 프레임을 모두 참고해서 더 효율적으로 압축하는 프레임 | 움직임이 중간에 있는 프레임 |
| GOP (Group Of Pictures) |
- 하나의 I 프레임을 기준으로 이어지는 프레임 묶음 - 보통 다음 I 프레임 전까지를 하나의 GOP로 봄 |
I B B P B B P 한 묶음 |
GOP가 길면 I 프레임이 적기 때문에 용량은 줄지만 중간 탐색·오류 복원이 불리하고, 짧으면 용량이 늘어납니다. 또한, I 프레임의 위치는 ABR이 화질을 바꿀 때 중요한 조건으로 사용됩니다.
2-3. 코덱과 컨테이너
코덱 (Codec)
앞에서 계속 살펴본 것처럼 동영상 원본의 크기는 너무 거대합니다. 그래서 저장하거나 전송하기 좋게 줄여 사용하는데, 이때 어떤 방식으로 줄이고 어떤 방식으로 다시 풀지 정한 규칙이 코덱입니다.

덱은 Coder와 Decoder의 합성어로, 영상을 압축하고 다시 복원하기 위한 규칙입니다.
H.264 같은 영상 코덱은 공간적 중복, 시간적 중복을 줄이고 I·P·B 프레임 구조, 예측, 변환, 양자화, 엔트로피 부호화 같은 과정을 통해 데이터를 줄입니다. 보통 YUV 계열 표현과 크로마 서브샘플링을 함께 활용해 사람이 덜 민감한 색 정보도 효율적으로 저장합니다.
대표적인 비디오 코덱들은 아래와 같습니다.
| 코덱 | 특징 | 같은 화질일 때 용량 |
| H.264 (AVC) | 가장 널리 쓰임, 호환성 최고. 사실상 기본값 | 기준 (100%) |
| H.265 (HEVC) | H.264의 약 절반 용량, 라이선스 비용 이슈 | ~50% |
| VP9 | 구글, 로열티 무료 | ~50% |
| AV1 | 차세대, 무료·고압축. 인코딩 매우 느림 | ~30~40% |
코덱은 알고리즘은 호환성, 용량, 인코딩/디코딩 속도 등 용도에 따라 선택해야 합니다.
컨테이너
영상 파일은 컨테이너(포장 상자) + 코덱(압축 방식)으로 이뤄집니다.
코덱은 “어떻게 압축할지”만 정하기 때문에 압축된 영상·오디오·자막을 하나로 묶는 포장 상자가 따로 필요합니다.
컨테이너는 비디오, 오디오, 자막, 메타데이터를 하나의 파일에 담는 규격입니다.

같은 .mp4 확장자라도 내부 코덱이 다를 수 있고, 같은 H.264 코덱이라도 MP4, MKV, TS 등 다른 컨테이너에 담길 수 있습니다.
여기서 비디오·오디오 등 여러 트랙을 하나의 컨테이너로 묶는 행위를 먹싱(Muxing)이라 합니다.
| 컨테이너 | 특징 |
| MP4 | 호환성 최고, 웹·모바일 표준 |
| MKV | 다중 트랙·자막 자유로움 |
| MOV | 애플이 개발한 멀티미디어 비디오 컨테이너 포맷 |
| TS | 방송·스트리밍 전송용 |
코덱을 모르면 파일을 열어볼 수 없기 때문에 같은 .mp4라도 안에 든 코덱이 다르면 재생이 안 될 수 있습니다.
3. 인코딩, 디코딩 그리고 트랜스코딩
3-1. 인코딩과 디코딩
영상에서 인코딩(Encoding)은 원본 영상 데이터를 코덱 규칙에 따라 압축하는 과정입니다.
인코딩은 연산량이 매우 많아서 오래 걸리고 CPU를 많이 사용합니다. 같은 코덱이라도 '얼마나 공들여 압축하느냐'에 따라 결과가 달라지는데, 이때 쓰이는 요소들을 조절하여 영상의 품질과 속도, 용량을 결정할 수 있습니다.
앞에서 살펴본 압축 방식들이 인코딩에 포함됩니다.
1) RGB → YUV + 크로마 서브샘플링 (지각적 중복)
2) 프레임을 I·P·B로 나눠 차이만 (시간적 중복)
3) 한 프레임 안 비슷한 영역 요약 (공간적 중복)
디코딩(Decoding)은 압축된 영상을 풀어 화면에 그릴 픽셀 프레임으로 되돌리는 과정입니다.
영상 재생기는 그 코덱의 디코더를 반드시 가져야 합니다. 없으면 소리는 나는데 화면이 안 나오거나 재생 불가 현상이 발생할 수 있습니다. 바로 이 문제 때문에 트랜스코딩이 필요해집니다.
3-2. 트랜스코딩
트랜스코딩은 이미 인코딩된 영상을 디코딩 후 다른 코덱/포맷/해상도/비트레이트로 변환하여 다시 인코딩하는 작업입니다. 스트리밍 환경에서 꼭 필요한 과정으로, 다양한 환경의 사용자가 영상 시청을 할 수 있도록 돕습니다.

트랜스코딩은 이미 압축된 것을 풀어서 또 다른 압축본으로 만드는데, 이미 손실된 걸 또 손실 압축하므로 화질이 더 떨어질 수 있습니다(세대 손실).
FFmpeg
트랜스코딩(디코딩 → 재인코딩)을 실제 코드로 실행할 때 사실상 표준처럼 쓰이는 도구가 FFmpeg입니다. 오픈소스 커맨드라인 도구이고 거의 모든 코덱·컨테이너를 다룹니다. 유튜브·넷플릭스를 비롯한 수많은 서비스의 내부 파이프라인에 들어가 있습니다.

아래는 input.mp4 파일을 1080p, 영상은 H.264, 오디오는 AAC로 트랜스코딩하여 output_1080p.mp4 파일로 변환하는 명령어입니다.
ffmpeg -i input.mp4 -vf scale=-2:1080 -c:v libx264 -c:a aac output_1080p.mp4
FFmpeg은 필터, 고급 기술, 하드웨어 가속 등 여러 기능을 제공합니다!
4. 전달: 스트리밍
영상을 시청자에게 보내는 방식은 파일을 건네줄 것인지 흘려보낼 것인지에 따라 다운로드와 스트리밍 두 가지로 나눌 수 있습니다.
4-1. 다운로드와 스트리밍
다운로드는 영상 파일 하나를 통째로 보냅니다. 시청자 받은 파일은 내 것이 되고, 다 받아야 온전히 쓸 수 있습니다. 그런데 영상은 파일이 크다 보니 다운로드 안에서도 다 받고 나서 재생하는 방식과 받는 중에 앞부분부터 재생하는 방식(Progressive Download)으로 갈립니다.
그럼에도 영상을 받으면서 재생하긴 하지만 결국 하나의 통파일을 처음부터 순서대로 받는 것이라 중간으로 건너뛰기(seek)도 불편하고 화질을 바꿀 수 없습니다. 스트리밍을 통해 이 문제를 해결할 수 있습니다.
스트리밍은 영상 재생을 위해 전체 파일을 보내지 말고, 하나의 영상 파일을 잘게 쪼개 필요한 만큼만 주는 방식입니다. 스트리밍을 위해서는 조각들에 대한 정보가 담긴 플레이리스트를 먼저 다운로드 받아야 합니다. 이를 바탕으로 작게 나눠진 영상 조각들 중에서 보고싶은 지점을 쉽게 찾아 볼 수 있고, 중간에 화질을 마음대로 변경할 수 있습니다.

4-2. 세그먼트와 버퍼링
현대 스트리밍은 영상을 작은 조각(Segment)으로 쪼갭니다. 보통 2~10초로 쪼개며, 6초 단위가 국룰이라고 합니다.
영상을 여러 조각으로 자르면 전체 영상을 다 받지 않아도 첫 조각부터 바로 재생할 수 있으며, 조각마다 다른 화질로 받을 수 있습니다. 물론 이를 위해 트랜스코딩 과정에서 미리 같은 영상을 화질별로 여러 개 만들어두어야 합니다.
쾌적한 시청을 위해 플레이어는 영상을 시청하는 동안 뒷 조각을 미리 받아 버퍼에 쌓아둡니다. 네트워크가 느려지더라도 버퍼에 다음 세그먼트가 존재한다면 기다릴 필요 없이 바로 재생이 가능하지만, 만약 버퍼에 다음 영상이 존재하지 않는다면 버퍼링이 발생합니다.
4-3. 매니페스트와 ABR
같은 영상을 4K·1080p·720p·480p로 트랜스코딩해 두고, 각각을 조각으로 쪼개어 저장합니다. 그리고 '어떤 화질의, 몇 번째 조각이, 어디 있는지' 적어둔 목차 파일을 만드는데 이것이 매니페스트(Manifest)입니다.

매니페스트 파일을 바탕으로 네트워크 상태에 따라 조각 단위로 화질을 자동 전환하는 것이 ABR(Adaptive Bitrate)입니다.
자동 화질 전환 기능을 효율적으로 사용하려면 화질이 골고루 준비되어 있어야 합니다. 고화질 영상만 제공한다면 버퍼링이 많이 발생할 것이고, 저화질 영상만 제공한다면 불필요하게 낮은 화질만 제공되기 때문입니다.
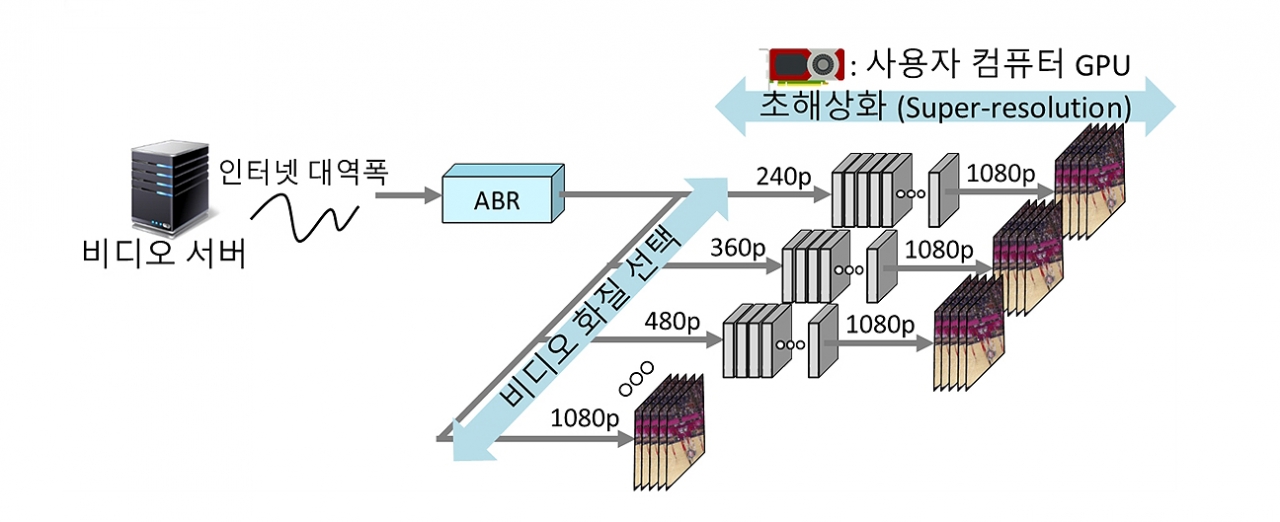
ABR 알고리즘은 여러 가지가 존재한다고 합니다.
- Throughput 기반 (대역폭 측정)
- 최근 N개 세그먼트 다운로드 속도 측정
- 간단하고, 반응이 빠름 / 네트워크 변동에 민감하여 화질 변경이 잦음
- Buffer 기반
- 버퍼에 쌓인 재생 시간을 모니터링
- 안정적이며, 버퍼링 방지에 좋음 / 반응이 느리고, 초기화질 결정에 어려움이 존재함
- 하이브리드 (Throughput + Buffer)
- 실제로 많은 플레이어들이 사용한다고 함
4-4. 스트리밍 프로토콜
스트리밍을 위한 별도 프로토콜이 존재하며, 대표적인 스트리밍 방식으로는 HLS와 MPEG-DASH가 있습니다. 두 방식 모두 기본 구조는 비슷합니다. 긴 영상을 몇 초 단위의 세그먼트로 나누고, 이 세그먼트들의 위치와 재생 순서를 적어둔 재생목록 또는 매니페스트 파일을 함께 제공합니다. 이 구조를 바탕으로 네트워크 상황에 따라 화질을 바꿀 수 있는 ABR이 가능하게 됩니다.
HLS와 DASH
서버에서 다수 시청자에게 영상을 배포하는 HTTP 기반 프로토콜의 양대 표준이 HLS와 DASH입니다. 조각(세그먼트)을 평범한 HTTP 파일로 주고받는 방식 덕분에 일반 웹서버·CDN에 사용되며 사실상 표준이 됐습니다.
| HLS (HTTP Live Streaming) | DASH (Dynamic Adaptive Streaming over HTTP) | |
| 만든 곳 | 애플 | 국제 표준(MPEG) |
| 매니페스트 | - 플레이리스트 - .m3u8 |
- MPD - .mpd |
| 조각 | - 전통적 .ts - 현대 .mp4(fMP4) |
.mp4(fMP4) |
| 코덱 제약 | 비교적 한정적 | 코덱 무관(유연) |
| 호환성 | 애플 생태계 필수 지원 | 웹·안드로이드 강세 |
예전에는 구분을 해서 사용했지만, 각각의 장단점이 존재하기 때문에 요즘은 CMAF를 사용하는 경우도 종종 있다고 합니다. CMAF는 HLS와 DASH 양쪽에서 사용할 수 있는 세그먼트 포맷으로 활용되어 있습니다. 공용 .mp4(FMP4)을 하나 만들어두고, HLS용 m3u8과 DASH용 mpd가 가리키도록 합니다.
플레이리스트
대부분의 동영상 플랫폼에서 사용하는 HLS는 2단 구조로 되어 있습니다. 먼저 화질 목록을 담은 마스터 플레이리스트가 있고, 각 화질마다 그 화질의 조각 목록을 담은 미디어 플레이리스트가 따로 있습니다.
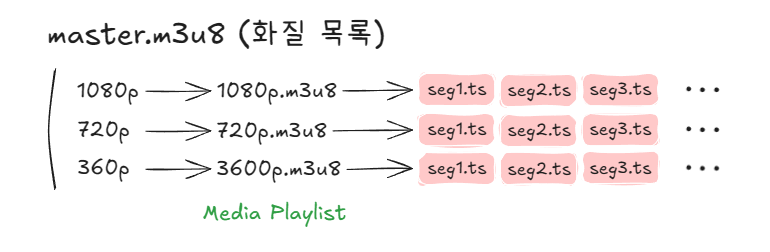
이 플레이리스트를 바탕으로 아래와 같이 영상 재생이 진행됩니다.
- 마스터 플레이리스트 파일(m3u8)을 다운로드하여 재생 가능한 화질 확인
- 네트워크 상황에 맞는 미디어 플레이리스트 선택
- 선택한 미디어 플레이리스트를 읽으며 세그먼트를 다운받으며 재생
- 재생하면서 네트워크 상황을 측정하여 상황에 맞는 화질로 자동 변경
키프레임 정렬
화질을 변경하기 위해 조각을 바꿔 끼우려면 그 조각이 혼자 완전하게 시작될 수 있어야 합니다. 조각이 이전 조각을 참고하는 P·B 프레임으로 시작하면 화질을 바꾼 순간 기준이 사라져 화면이 깨지기 때문에 모든 조각은 I 프레임으로 시작하도록 만들고, 화질이 달라도 조각 경계를 똑같이 맞춥니다. 이를 키프레임 정렬이라고 합니다.

결국, 스트리밍 조각 길이와 GOP 길이가 맞아야 ABR이 정상적으로 동작합니다. 만약 둘이 일치하지 않는다면 다른 조각이 필요하게 될 수 있습니다.
라이브 스트리밍의 경우
VOD는 미리 다 처리해두므로 영상 재생 시 별도 수집 과정이 필요하지 않습니다. 하지만, 라이브의 경우 실시간으로 수집 구간 작업이 필요합니다. 이 구간은 '한 명(방송자)이 서버로 끊김 없이 올린다'가 목표이기 때문에 배포(HLS/DASH)와는 다른 프로토콜을 사용합니다.
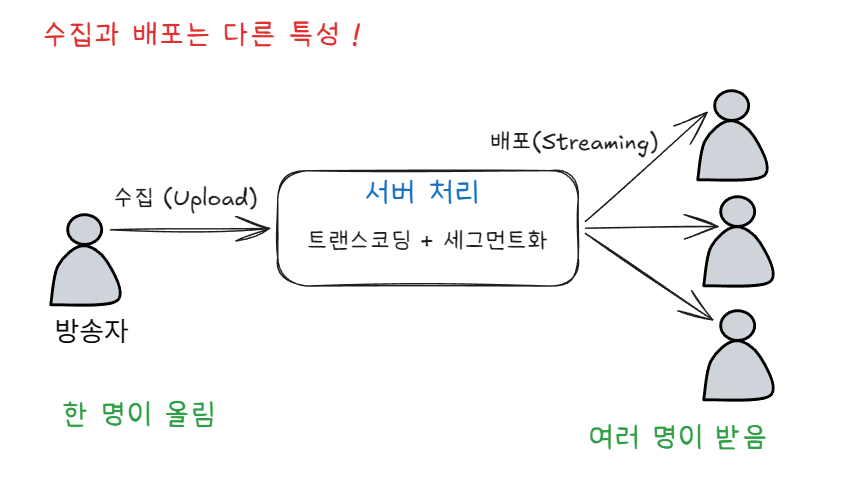
라이브 파이프라인은 보통 방송자가 RTMP(또는 SRT)로 올리면 서버가 실시간 트랜스코딩·세그먼트화해서 HLS/DASH로 재생할 수 있도록 제공합니다. 영상을 올리고 내리는 프로토콜이 다르게 사용됩니다.
| 프로토콜 | 구간 | 특징 |
| RTMP | 수집 | - 오래된 사실상 표준 - 지연이 낮고 OBS 등 송출 도구 호환성이 좋다. 단 옛 기술이라 시청자 배포용으로는 부적합 |
| SRT | 수집 | - RTMP의 현대적 대안 - 불안정하거나 먼 네트워크에서도 손실을 복구하며 안정적으로 전송 |
| WebRTC | 수집·배포 양쪽 | - 초저지연(1초 미만) - 양방향 실시간 상호작용 용도 |
| HLS / DASH | 배포 | - HTTP 기반, 확장성 최고 - 단, 조각을 모으느라 지연 발생 |
5. 영상 품질은 어떻게 알까
5-1. 영상 품질 지표
영상의 품질을 알아보는 가장 쉬운 방법은 사람이 직접 눈과 귀로 확인하는 것입니다. 하지만, 세세한 차이까지 다 알 수 없고 모든 영상을 사람이 검토하는 것은 매우 오랜 시간이 걸립니다. 또한, 일정 품질 목표가 있다고 한들 '봐줄 만한가'가 모호합니다.
화질을 수치화하는 방식이 있는데, 크게 세 가지가 사용됩니다.
| PSNR (픽셀 오차) | SSIM (구조적 유사도) | VMAF (사람 체감 예측) | |
| 세대 | 1세대 | 2세대 | 3세대 (현재 표준) |
| 무엇을 재나 | 픽셀이 얼마나 다른가 | 구조(윤곽·명암 패턴)가 얼마나 비슷한가 | 사람이 몇 점이라 느낄까 |
| 원리 | 원본↔압축본의 수학적 픽셀 오차 | 사람은 개별 픽셀이 아닌 "전체 형태"로 인식한다는 점 활용 | 사람이 직접 매긴 평가를 학습해 예측 (여러 지표를 fusion) |
| 결과 형태 | dB (높을수록 좋음) | 0~1 (1에 가까울수록 좋음) | 0~100 점수 |
| 사람 체감과의 일치 | 낮음 (괴리 큼) | 중간 | 높음 |
| 약점 | 픽셀 오차 작아도 눈엔 거슬리거나 그 반대 | 픽셀보단 낫지만 여전히 체감과 거리 | 결국 예측값 (진짜 기준은 사람 평가 MOS) |
낮은 세대일수록 계산이 빠르고 단순하다는 장점이 있지만, 그 수치가 영상 품질을 대표하기 부정확하다는 단점이 있습니다. 따라서 실제 사용할 때에는 전체 영상에 대한 검수는 PSNR과 SSIM으로 빠르게 처리하고, 최종 품질 판단은 VMAF로 하는 방식으로 섞기도 한다고 합니다.
VMAF가 있으면 화질을 점수로 관리할 수 있습니다. 이걸 활용하면 'VMAF 93점을 유지하면서 비트레이트는 최소로'같은 목표를 세우고 최적화를 진행할 수 있게 됩니다.
참고로 VMAF 6점 차이는 인간의 시각으로 인지할 수 있는 최소 단위인 1JND (Just Noticeable Difference)라고 한다고 하네요!!
5-2. 영상 품질 최적점 찾기
영상 품질과 용량은 반비례합니다. 용량이 커지면 품질이 높아지고, 그 반대도 마찬가지이기 때문에 품질과 용량의 균형점을 잘 잡아야 합니다. 이를 위해 CRF라는 방식을 사용하여 품질을 기준으로 용량을 결정해 압축할 수 있습니다. CRF 비트레이트가 아니라 품질을 기준으로 인코딩합니다. CRF 말고도 CBR, VBR 등 방식이 존재하는데, 간단하게 아래처럼 정리할 수 있습니다.
CBR → 비트레이트 고정
VBR → 평균 비트레이트 중심
CRF → 품질 기준 고정예를 들어, CRF 값을 하나 정하면 인코더는 비슷한 체감 품질을 유지하기 위해 필요한 만큼 비트를 사용합니다.
CRF는 파일 크기를 정하는 방식이 아니라 원하는 품질을 정하는 방식입니다. 같은 CRF 값이라도 토크쇼는 파일이 작게 나오고, 스포츠 영상은 훨씬 크게 나올 수 있습니다. 품질을 유지하기 위해 필요한 데이터 양이 다르기 때문입니다.
그렇다면 적절한 CRF 값을 설정해야 하는데, 여기서 VMAF같은 품질 지표가 등장합니다. 같은 영상을 여러 CRF 값으로 인코딩한 뒤 품질을 측정해서 비교해볼 수 있습니다.
CRF 18 → 파일 큼, 화질 높음
CRF 23 → 균형점
CRF 28 → 파일 작음, 화질 낮음그리고 각 결과의 비트레이트와 VMAF를 비교합니다.
CRF 값 변경 → 인코딩 → 비트레이트 측정 → VMAF 측정 → 품질 대비 효율 비교이 과정을 통해 어느 지점부터 화질 차이가 거의 느껴지지 않는지, 어느 지점부터 비트를 더 써도 품질 향상이 크지 않은지를 확인할 수 있습니다.
CRF와 VMAF가 헷갈릴 수 있는데, CRF는 인코딩 설정값 / VMAF는 품질 측정 점수라는 차이가 있습니다.
6. 마무리
최대한 흐름 중심으로 내용을 연결시키려고 했는데, 막상 작성해보니 조금 장황한 것 같아서 슬픕니다.. 다소 깊어진 내용이나 영상 트랜스코딩에는 불필요했던 개념들이 들어가기도 했네요. 그래도 영상 처리를 위한 기초 개념을 전체적으로 한 번 훑어본다는 느낌으로 읽어보면 좋을 것 같습니다.
처음부터 모든 개념이 필요하지는 않지만, 기본적인 영상 트랜스코딩 작업을 수행하면서 '기본적으로 올바른' 결과물을 내는 것만으로도 상당히 많은 설정이 들어갑니다. 이들을 모르고 사용할 수 있는데, 그렇다면 나중에 품질을 측정하거나 고도화를 진행할 때 기본적인 곳에서부터 문제가 발생할 수 있습니다.
실제로 잘 모른 채로 영상 트랜스코딩을 완료됐지만, 조금씩 아는 것이 생기면서 저는 제대로 한 것이 아니었음을 깨달았던 기억이 있습니다. 그래서 기본 개념을 익히고 FFmpeg 명령어들이 영상에 어떤 영향을 미치는지 체감할 필요가 있겠다고 느껴서 글을 작성했습니다.