

💡이 글은 동시성 처리가 필요한 상황에서 서비스와 게시글의 특성을 통해 효율적으로 조회수를 카운팅 할 수 있는 방법에 대해 살펴봅니다. 동시성을 처리하는 가장 기본적인 작업만 되어 있는 상태부터 세분화하여 업데이트를 위한 락을 줄여가는 방식으로 전개됩니다.
이전 글에서 조회수 카운팅 관련하여 크게 두 가지 문제를 다뤄봤습니다. 하나는 맞춤형 집계를 위한 조회수 카운팅 정책 설정이고, 다른 하나는 여러 요청이 발생할 때의 동시성 문제입니다. 조회수 정책 관련 글과 동시성 처리 관련 글에서 각각의 내용을 확인하실 수 있습니다.
이번에는 사용자가 많아질 경우 게시글 조회마다 발생하는 조회수 업데이트로 인한 성능에 대한 이야기를 해보겠습니다. 현재, update쿼리를 직접 사용하여 업데이트 할 때, 레코드에 x락을 걸게 됩니다. 락의 발생이 많아질수록 성능은 저하되기 때문에 실시간성과 어느정도 타협하여 성능을 끌어올릴 수 있습니다.
0. 상황 정의
현재 서비스는 회원/비회원 모두가 사용 가능한 기술 블로그입니다. 동아리 부원만 회원 가입과 글 작성이 가능하고, 현재 부원은 80명 정도 존재합니다. 따라서 게시글 조회(Read)에 비해 게시글 작성(Write)은 확실히 적게 발생할 것임을 예상할 수 있습니다(요청이 많이 발생한다면!). 이에 따라 게시글 수에 비해 읽기 요청이 많다는 가정으로 진행하였습니다.
조회수 집계 정책에 대해 설정해 놓은 것이 있어 더더욱 문제가 발생할 가능성이 적지만, 집계 정책과 별도로 단순 +1 상황을 기준으로 성능 개선을 생각해보겠습니다.
기술 블로그 특성 상 특정 키워드 검색으로 방문을 가장 많이 합니다. 하지만, 이는 사용자마다 다르며, 예측이 매우 어렵기 때문에 배제하고자 합니다. 특정 키워드를 통해 어떤 게시글로 유입된 사용자가 다른 글을 조회하고자 한다면 주로 기술 블로그 메인 화면 최상단에 배치된 게시글을 조회할 것입니다. 현재는 최신 순으로 배치하며, 만약 다른 방식을 추가로 도입한다면 조건을 걸어 인기글로 지정된 가장 최근 게시글을 상단에 배치할 수 있습니다.
페이지 단위로 10개씩 메인 화면에 배치가 되므로 게시글 작성 시간을 고려하여 조회수 업데이트 방식을 살펴보겠습니다.
간단하게 테스트용 프로젝트를 생성하고 코드를 작성한 후 서버를 3개 띄운 뒤 추이 파악을 위한 테스트를 진행해보았습니다.
1. 모든 게시글 통합
1) 조회 시 DB 업데이트
동시성 처리를 진행한 현재 상태 그대로 진행하는 방식입니다. 모든 게시글을 조회할 때마다 바로 DB에 +1 업데이트 해줍니다.

딱히 처리해 줄 것이 없어 구현이 매우 간단하고, 저희 서비스처럼 사용자가 많지 않은 경우 적합합니다. 하지만 조회 요청이 많은 경우 매번 락 경합으로 인해 성능에 문제가 생길 가능성이 높습니다.
// repository
public interface PostRepository extends JpaRepository<Post, Long> {
@Modifying
@Query("UPDATE Post p SET p.viewCount = p.viewCount + 1 WHERE p.id = :postId")
void incrementViewCount(@Param("postId") Long postId);
}
// service
@Transactional
public SuccessResponse<?> getPostDetail(Long postId) {
Post post = postRepository.findById(postId).orElseThrow();
postRepository.incrementViewCount(postId);
// ...
}딱히 처리해 줄 것이 없어 구현이 매우 간단하고, 저희 서비스처럼 사용자가 많지 않은 경우 적합합니다. 하지만 조회 요청이 많은 경우 매번 락 경합으로 인해 성능에 문제가 생길 가능성이 높습니다.

Jmeter를 사용해 1분 간 테스트를 진행해보았습니다. 다만, 테스트용 프로젝트이며, 로컬 환경이므로 테스트 결과 값보단 다른 방식과의 추이를 비교하는 정도로 사용하면 좋을 것 같습니다.
해당 방식의 경우 사용자 요청 간 텀이 없을 때에 비해 텀이 있는 경우 평균 속도가 높은 것을 볼 수 있습니다. 텀으로 인해 전체 처리 속도는 느려졌지만, 비교적 느슨한 요청으로 인해 락 경합이 줄어들어 평균적인 속도가 빨라진 것입니다.
2) 카운팅 후 DB 업데이트
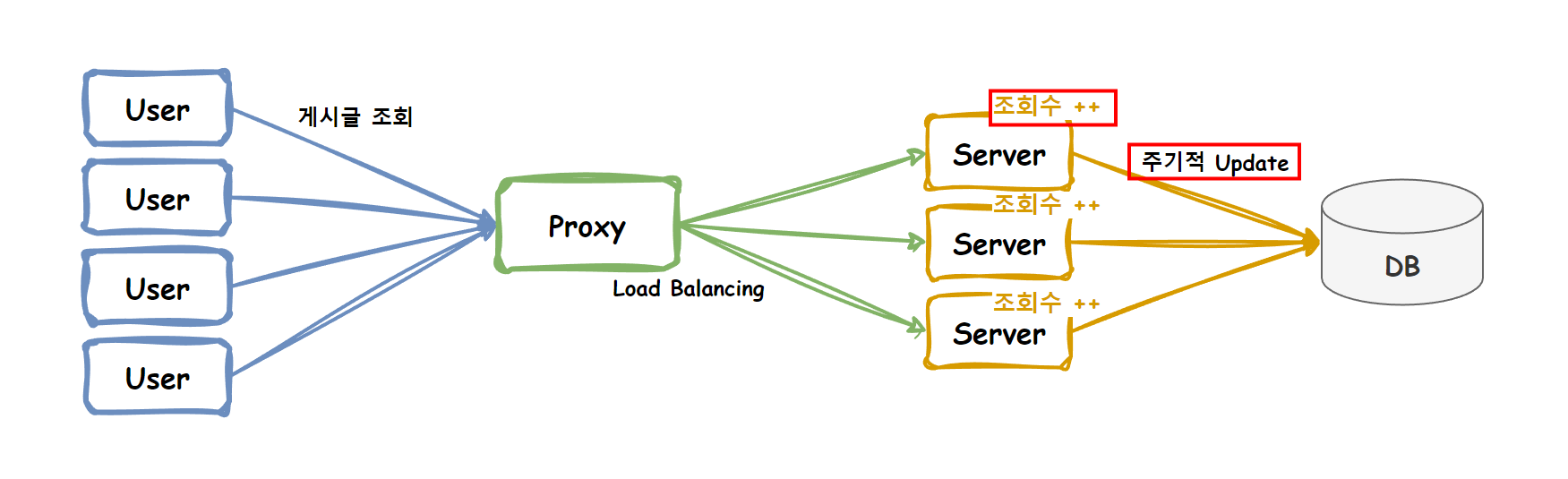
조회수를 바로 업데이트 하지 않고, 어딘가에 쌓아놓은 후 주기적으로 DB에 업데이트 하는 방법입니다. 서버마다 메모리에 조회수를 카운팅하는 방식과 Redis로 대표되는 저장소에 카운팅 후 업데이트 하는 방식이 대표적입니다.
서버마다 인 메모리 카운팅 -> DB 업데이트
게시글 조회 요청이 들어오면 각 서버는 메모리에 게시글 별 조회수를 카운팅하고, 주기적으로 DB에 업데이트 합니다. 이 경우, 각 서버에서 로컬 변수를 사용하거나 로컬 캐시에 저장하는 방법이 있습니다. 조회수는 단순 업데이트하는 간단한 작업이기 때문에 ConcurrentHashMap을 사용해보겠습니다.
// service
@Transactional
public SuccessResponse<?> getPostDetailInMemoryCount(Long postId) {
Post post = postRepository.findById(postId).orElseThrow();
inMemoryViewCountStore.increment(postId);
// ...
}
@Component
public class InMemoryViewCountStore {
private final ConcurrentHashMap<Long, AtomicInteger> viewCountMap = new ConcurrentHashMap<>();
public void increment(Long postId) {
viewCountMap.computeIfAbsent(postId, k -> new AtomicInteger(0)).incrementAndGet();
}
public Map<Long, AtomicInteger> getAllCounts() {
return viewCountMap;
}
}
// 주기적 update
@Scheduled(fixedRate = 10000)
@Transactional
public void flushToDb() {
Map<Long, AtomicInteger> countMap = inMemoryViewCountStore.getAllCounts();
if(countMap.isEmpty()) return;
int increment = 0;
for(Map.Entry<Long, AtomicInteger> entry : countMap.entrySet()){
Long postId = entry.getKey();
increment = entry.getValue().getAndSet(0);
if(increment > 0)
postRepository.incrementViewCount(postId, increment);
}
log.info("인메모리 조회수 반영 완료, 대상 {}건", increment);
}ConcurrentHashMap과 AtomicInteger를 사용하여 원자적 연산을 가능하게 했습니다. ConcurrentHashMap과 AtomicInteger는 내부적으로 CAS 연산을 수행하기 때문에 여러 스레드가 동시에 값을 변화시켜도 lock-free 상태로 빠르고 안전하게 업데이트를 수행합니다. 정말정말 최악의 경우 스핀락이 걸려 무한히 돌게 될 수 있는데, 이 경우 제한 횟수를 두어 한계에 도달하면 block 후 처리하는 방식으로 해결할 수 있습니다.
각 서버마다 자체적으로 조회수를 카운팅하고 주기적으로 update 해주므로 update 쿼리 자체의 발생이 적습니다. 따라서 락 경합이 적어지고 이로 인한 성능 문제가 매우 줄어듭니다. 또한, 추가적인 인프라 구성이 필요 없기 때문에 이 방법 또한 간단하게 구현할 수 있습니다.
하지만, 조회수를 실시간으로 정확하게 제공하지 못한다는 단점이 있습니다. 사용자에게 보여지는 조회수는 중요하지 않은 경우가 많기 때문에 괜찮지만, 실시간성이 높아야 하는 경우 적합하지 않습니다. 또한, 사용 중인 서버가 죽을 때, 데이터 처리가 적절히 이뤄지지 않는다면 일부 누락될 수 있습니다. 데이터가 누락되면 안되는 서비스의 경우 Graceful Shotdown을 고려해야 합니다.

DB에서 락 경합 자체가 거의 없기 때문에 요청에 텀을 주지 않았을 때 엄청나게 처리량이 많아지는 것을 확인할 수 있습니다. 텀이 있을 때 역시 전반적으로 매우 빠른 속도를 보여줍니다.
Redis 카운팅 -> DB 업데이트
이 전 방식과 비슷한데, 각 서버에서 조회수를 카운팅하는 것이 아닌 Redis에 카운팅을 하고, 주기적으로 업데이트 하는 방법입니다.

작성한 기본적인 코드는 아래와 같습니다. Redis를 사용할 때, 주기적 Update를 스케줄링한다면 여러 서버에서 동시에 실행되지 않도록 방지하는 코드를 추가해야 합니다.
// service
@Transactional
public SuccessResponse<?> getPostDetailRedis(Long postId) {
String key = "post:view:" + postId;
redisUtil.increment(key);
// ...
}
@RequiredArgsConstructor
@Component
public class RedisUtil {
private final StringRedisTemplate stringRedisTemplate;
public Set<String> scanKeys(String pattern) {
Set<String> keys = new HashSet<>();
ScanOptions options = ScanOptions.scanOptions().match(pattern).count(1000).build();
Cursor<byte[]> cursor = stringRedisTemplate.getConnectionFactory().getConnection().scan(options);
while (cursor.hasNext()) {
keys.add(new String(cursor.next(), StandardCharsets.UTF_8));
}
try {
cursor.close();
} catch (Exception e) {
//
}
return keys;
}
public Long increment(String key) {
return stringRedisTemplate.opsForValue().increment(key, 1);
}
// ...
}
스케줄링 작업을 구성할 때 주의해야 할 또 다른 점은 DB 업데이트 시 redis 키를 삭제하면 안 된다는 것입니다. 키를 삭제할 때, 다른 서버에서 조회수 카운팅을 한다면 그만큼 데이터가 손실될 수 있기 때문입니다. 따라서 업데이트 시에는 키를 삭제하지 말고 값을 차감하는 방식으로 구현하는 것이 좋습니다.
// 주기적 update
@Slf4j
@Component
@RequiredArgsConstructor
public class RedisFlushScheduler {
private final RedisUtil redisUtil;
private final PostRepository postRepository;
@Scheduled(fixedRate = 5000)
@Transactional
public void flushRedisCountsToDb() {
Set<String> keys = redisUtil.scanKeys("post:view:*");
if (keys.isEmpty()) return;
for (String key : keys) {
String value = redisUtil.getData(key);
if (value != null) {
int inc = Integer.parseInt(value);
String[] parts = key.split(":");
if (parts.length == 3) {
try {
Long postId = Long.parseLong(parts[2]);
if (inc > 0) {
postRepository.incrementViewCount(postId, inc);
redisUtil.decrement(key, inc);
// redisUtil.deleteData(key); 삭제하면 안됨!!
log.info("Redis 키 {}의 조회수 {}를 DB에 반영 완료", key, inc);
}
} catch (NumberFormatException e) {
log.error("키 {}에서 postId 파싱 실패", key, e);
}
}
}
}
}
}
모든 서버에서 레디스에 먼저 조회수를 올리고, DB 업데이트를 한 번만 수행하기 때문에 락으로 인한 충돌은 더욱 적어집니다. 하지만, 추가적인 인프라 구성이 필요하다는 점, 네트워크 병목이 생길 가능성이 높아진다는 점과 게시글이 많아질수록 레디스에서 관리해야 하는 데이터가 많아지기 때문에 자원 소모가 갈수록 커진다는 단점들이 있습니다.

이 방식도 마찬가지로 요청 간 텀이 없을 경우 처리량이 매우 많아집니다. 이전 방식보다 DB 업데이트는 적어지지만, 서버 개수가 3개 뿐이기 때문에 큰 의미는 없을 것 같습니다. 레디스를 사용하는 경우 레디스 자체가 단일 병목 지점이 될 수 있고, 네트워크를 거치는 시간이 길어지기 때문에 해당 사항 역시 고려해야 합니다.
2. 메인 페이지 게시글과 일반 게시글 분리
앞에서 살펴본 방법들을 조합하여 각각 메인 페이지에 노출될 게시글과 일반 게시글에 적용하는 방법을 사용할 수도 있습니다. 이렇게 된다면 실질적인 성능은 개선하고, 불필요한 메모리나 외부 자원 사용을 더욱 줄일 수 있습니다.
메인 페이지 게시글은 카운팅, 일반 게시글은 DB 업데이트

조회가 적을 것으로 예상되는 일반 게시글은 따로 처리하지 않고 바로 DB에 업데이트합니다. 메인 페이지에 노출될 최근 게시글은 위에서 살펴본 것처럼 따로 카운팅을 한 후 DB에 주기적으로 업데이트합니다. 이렇게 게시글을 둘로 나누어 작업하면 Redis에 올라갈 데이터의 양이 한정되기 때문에 자원 소모가 적다는 장점도 있습니다. 조회수가 몰릴 게시글은 당장의 정합성보다 성능이 중요할 수 있기 때문에 이렇게 나누어 적용하는 방식도 좋은 것 같습니다.
구현이 더욱 까다롭다는 점과 동기화 시 새로운 글 작성을 고려하여 key를 삭제하고 추가해줘야 한다는 주의점도 있습니다.
사용자가 많지도 않으며, 기술 블로그라는 서비스 특성 상 이번 글에서 살펴본 내용들을 적용하지는 않고 맨 처음 소개한 조회 시 바로 update 방식으로 유지할 것입니다. 하지만, 다른 서비스 혹은 사용자가 많은 경우라면 고민해 본 내용들을 효과적으로 적용할 수 있을 것 같습니다! 여러 경우를 함께 살펴보면서 흐릿했던 정보들이 조금은 뚜렷해진 느낌입니다.
'Project' 카테고리의 다른 글
| [O+T] 테스트 준비하기 (2) | 2026.04.28 |
|---|---|
| 다중 기기 환경에서의 푸시 알림 (0) | 2025.04.03 |
| 조회수 카운팅 시 동시성 문제 (0) | 2025.03.23 |
| 회원과 비회원을 고려한 복합 조회수 카운팅 정책 (0) | 2025.03.20 |
| Bulk 연산으로 Write 작업 개선하기 (0) | 2025.03.13 |