

병목 지점 탐색 및 개선 결과 확인을 위해 테스트 환경을 구축한 내용입니다.
프로젝트 내에 병목 지점으로 의심되는 부분은 많지만, 막상 테스트를 진행하지 않아 정말 개선이 필요한 지점인지, 또, 어느 규모에서 얼마나 문제인지 구체적으로 알 수 없었습니다.
의심에 대한 가설을 세우고, 테스트를 진행하여 실제 병목 지점을 파악하고, 이유를 찾아가며 개선 후 검증하는 절차를 거쳐가며 문제 지점부터 해결까지 지표 기반으로 진행하고자 합니다.
( 가설 -> 테스트 -> 병목 지점 선정 -> 개선 -> 검증 -> 결과 )
User API 서버의 테스트 및 개선을 위한 환경 구축 과정을 기록합니다.
더미 데이터 준비
데이터 규모에 따라 응답 시간이 달라집니다. 너무 작거나 큰 규모의 데이터를 가진 환경에서는 정확한 문제 파악 및 개선 측정이 어렵습니다.
이 규모를 여러 프리셋으로 지정해놓고, 필요한만큼 변경해가며 테스트를 진행하기 위한 목적으로 스크립트를 작성했습니다.
데이터 선정
현재 프로젝트에는 총 26개의 테이블이 존재하는데, 21개의 테이블을 채우고, 관련 없다고 판단한 5개의 테이블은 빈 상태로 두었습니다.
시드 대상 (21개)
| 그룹 | 테이블 | FK 의존 | 비고 |
| 메타데이터 | category | 없음 | 고정 데이터 직접 INSERT (seed-metadata.sql) |
| tag | category | 고정 데이터 직접 INSERT (seed-metadata.sql) | |
| mood_category | 없음 | V8에서 8개 시드됨 → 스킵 | |
| mood_tag | mood_category | V8에서 31개 시드됨 → 스킵 | |
| 회원 | member | 없음 | 최상위 |
| preferred_tag | member, tag | 회원당 3~5개 | |
| member_radar_preference | member (1:1) | 회원당 1개 | |
| 미디어 | media | member | 공통 부모 |
| series | media | media_type='SERIES' | |
| contents | media, series(nullable) | media_type='CONTENTS' | |
| short_form | media, series/contents(nullable) | media_type='SHORT_FORM' | |
| media_tag | media, tag | 미디어당 2~4개 | |
| media_mood_tag | media, mood_tag | 미디어당 1~3개 | |
| media_metrics | media (1:1) | 미디어당 1개 | |
| 상호작용 | bookmark | member, media | |
| likes | member, media | ||
| comment | member, contents | contents에만 | |
| 시청 | watch_history | member, contents | UK(member, contents) |
| playback | member, contents | UK(member, contents) | |
| click_event | member, short_form | ||
| 분위기 | member_mood_refresh | member | 회원당 0~1개 |
시드 제외 (5개)
아래 5개 테이블은 트랜스코딩 서버 관련 테이블이므로, User-Api 서버의 테스트 대상에서 제외했습니다.
| 테이블 | 제외 이유 |
| ingest_job | 트랜스코딩 파이프라인용 |
| ingest_command | 위와 동일 |
| transcode_outbox | 위와 동일 |
| flyway_schema_history | Flyway 내부 관리용 |
| shedlock | ShedLock 내부 잠금용 |
데이터 규모
데이터 규모를 프리셋별로 나눠, 점진적으로 테스트해 볼 수 있도록 구분했습니다.
프리셋별 규모
xl은 member 10,000 고정, 나머지 테이블만 large 대비 크기를 늘렸습니다. 요청 수는 VU로 조절이 가능하기 때문에, 늘리는 것이 의미 없다고 판단했습니다.
small / medium / large / xl로 구분하여 규모별로 데이터를 삽입할 수 있도록 구성했습니다.
| 테이블 | small | medium | large | xl |
| member | 100 | 1,000 | 10,000 | 10,000 |
| category | 고정 | 고정 | 고정 | 고정 |
| tag | 고정 | 고정 | 고정 | 고정 |
| media | 1,000 | 10,000 | 50,000 | 500,000 |
| ┗ series (10%) | 100 | 1,000 | 5,000 | 50,000 |
| ┗ contents (60%) | 600 | 6,000 | 30,000 | 300,000 |
| ┗ short_form (30%) | 300 | 3,000 | 15,000 | 150,000 |
| media_tag | 3,000 | 30,000 | 150,000 | 1,500,000 |
| media_mood_tag | 2,000 | 20,000 | 100,000 | 1,000,000 |
| media_metrics | 1,000 | 10,000 | 50,000 | 500,000 |
| preferred_tag | 400 | 4,000 | 40,000 | 40,000 |
| member_radar_preference | 100 | 1,000 | 10,000 | 10,000 |
| bookmark | 5,000 | 50,000 | 200,000 | 2,000,000 |
| likes | 5,000 | 50,000 | 200,000 | 2,000,000 |
| comment | 3,000 | 30,000 | 100,000 | 1,000,000 |
| watch_history | 10,000 | 100,000 | 500,000 | 5,000,000 |
| playback | 5,000 | 50,000 | 200,000 | 2,000,000 |
| click_event | 3,000 | 30,000 | 100,000 | 1,000,000 |
| member_mood_refresh | 50 | 500 | 5,000 | 5,000 |
고정 메타데이터 (category / tag)
시드 스크립트로 직접 생성. OTT 서비스에 맞는 장르/테마 기반.
Category
| id | name |
| 1 | 장르 |
| 2 | 분위기 |
| 3 | 시청상황 |
| 4 | 테마 |
Tag
| category | tags |
| 장르 | 액션, 로맨스, SF, 스릴러, 코미디, 드라마, 호러, 판타지, 다큐멘터리, 애니메이션 |
| 분위기 | 긴장감, 따뜻한, 유쾌한, 어두운, 감동적인 |
| 시청상황 | 혼자볼때, 연인과, 가족과, 심심할때, 잠들기전 |
| 테마 | 성장, 복수, 우정, 가족, 사랑, 생존, 범죄, 일상 |
더미 데이터는 프로시저로 작성하고, 호출하는 형식으로 작성했습니다.
[더미 데이터 프로시저]
-- =============================================
-- OTT 테스트 데이터 시드 프로시저
-- 사용법:
-- mysql -u ott -p ott < scripts/seed-procedures.sql
-- mysql -u ott -p ott -e "CALL seed_all('medium');"
-- =============================================
DELIMITER //
DROP PROCEDURE IF EXISTS seed_all //
CREATE PROCEDURE seed_all(IN p_preset VARCHAR(10))
proc_body: BEGIN
-- =============================================
-- CONFIGURATION
-- =============================================
IF p_preset NOT IN ('small', 'medium', 'large', 'xl') THEN
SELECT CONCAT('ERROR: Unknown preset "', p_preset, '". Use: small, medium, large, xl') AS error;
LEAVE proc_body;
END IF;
-- Verify metadata
IF (SELECT COUNT(*) FROM category) < 4 OR (SELECT COUNT(*) FROM tag) < 28 THEN
SELECT 'ERROR: Run seed-metadata.sql first!' AS error;
LEAVE proc_body;
END IF;
-- Base counts
IF p_preset = 'small' THEN
SET @v_member = 100, @v_series = 100, @v_contents = 600, @v_sf = 300;
SET @v_bookmark = 5000, @v_likes = 5000, @v_comment = 3000;
SET @v_watch = 10000, @v_playback = 5000, @v_click = 3000;
ELSEIF p_preset = 'medium' THEN
SET @v_member = 1000, @v_series = 1000, @v_contents = 6000, @v_sf = 3000;
SET @v_bookmark = 50000, @v_likes = 50000, @v_comment = 30000;
SET @v_watch = 100000, @v_playback = 50000, @v_click = 30000;
ELSEIF p_preset = 'large' THEN
SET @v_member = 10000, @v_series = 5000, @v_contents = 30000, @v_sf = 15000;
SET @v_bookmark = 200000, @v_likes = 200000, @v_comment = 100000;
SET @v_watch = 500000, @v_playback = 200000, @v_click = 100000;
ELSEIF p_preset = 'xl' THEN
SET @v_member = 10000, @v_series = 50000, @v_contents = 300000, @v_sf = 150000;
SET @v_bookmark = 2000000, @v_likes = 2000000, @v_comment = 1000000;
SET @v_watch = 5000000, @v_playback = 2000000, @v_click = 1000000;
END IF;
SET @v_media = @v_series + @v_contents + @v_sf;
-- =============================================
-- SETUP: Sequence table (1..10000, cross join for larger)
-- =============================================
DROP TABLE IF EXISTS _seed_seq;
CREATE TABLE _seed_seq (n INT UNSIGNED NOT NULL PRIMARY KEY);
SET @@cte_max_recursion_depth = 10000;
INSERT INTO _seed_seq
WITH RECURSIVE seq AS (SELECT 1 AS n UNION ALL SELECT n + 1 FROM seq WHERE n < 10000)
SELECT n FROM seq;
SET FOREIGN_KEY_CHECKS = 0;
SET UNIQUE_CHECKS = 0;
SET @start_time = NOW();
SELECT CONCAT('Starting seed: preset=', p_preset, ', members=', @v_member, ', media=', @v_media) AS progress;
-- =============================================
-- 1. MEMBER
-- =============================================
INSERT INTO member (email, password, nickname, role, provider, provider_id, refresh_token, onboarding_completed, created_date, modified_date, status)
SELECT
CONCAT('testuser', rn, '@test.com'),
NULL,
CONCAT('TestUser', rn),
CASE
WHEN rn <= FLOOR(@v_member * 0.90) THEN 'MEMBER'
WHEN rn <= FLOOR(@v_member * 0.95) THEN 'EDITOR'
ELSE 'ADMIN'
END,
'KAKAO',
CONCAT('kakao_test_', rn),
NULL,
TRUE,
DATE_SUB(NOW(), INTERVAL FLOOR(RAND(rn) * 365) DAY),
NOW(),
'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_member/10000.0)) nums
WHERE rn <= @v_member;
SET @m_start = LAST_INSERT_ID();
SET @m_end = @m_start + @v_member - 1;
SET @up_start = @m_start + FLOOR(@v_member * 0.90);
SET @up_count = @v_member - FLOOR(@v_member * 0.90);
SELECT CONCAT('[1/16] member: ', @v_member) AS progress;
-- =============================================
-- 2. MEMBER_RADAR_PREFERENCE (1:1 with member)
-- =============================================
INSERT INTO member_radar_preference (member_id, popularity, immersion, mania, recency, re_watch, created_date, modified_date, status)
SELECT
@m_start + rn - 1,
FLOOR(RAND(rn) * 101),
FLOOR(RAND(rn + 100000) * 101),
FLOOR(RAND(rn + 200000) * 101),
FLOOR(RAND(rn + 300000) * 101),
FLOOR(RAND(rn + 400000) * 101),
NOW(), NOW(), 'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_member/10000.0)) nums
WHERE rn <= @v_member;
SELECT CONCAT('[2/16] member_radar_preference: ', @v_member) AS progress;
-- =============================================
-- 3. PREFERRED_TAG (4 per member, offsets 0/7/14/21 guarantee uniqueness in 28 tags)
-- =============================================
INSERT INTO preferred_tag (member_id, tag_id, created_date, modified_date, status)
SELECT
@m_start + nums.rn - 1,
((nums.rn - 1 + t.offset) % 28) + 1,
NOW(), NOW(), 'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_member/10000.0)) nums
CROSS JOIN (SELECT 0 AS offset UNION ALL SELECT 7 UNION ALL SELECT 14 UNION ALL SELECT 21) t
WHERE nums.rn <= @v_member;
SELECT CONCAT('[3/16] preferred_tag: ', @v_member * 4) AS progress;
-- =============================================
-- 4. MEDIA (SERIES) + SERIES
-- =============================================
INSERT INTO media (uploader_id, title, description, poster_url, thumbnail_url, bookmark_count, likes_count, media_type, public_status, media_status, created_date, modified_date, status)
SELECT
@up_start + FLOOR(RAND(rn) * @up_count),
CONCAT('시리즈 ', rn),
CONCAT('시리즈 ', rn, '의 설명입니다.'),
CONCAT('/posters/series_', rn, '.jpg'),
CONCAT('/thumbnails/series_', rn, '.jpg'),
FLOOR(RAND(rn + 100000) * 200),
FLOOR(RAND(rn + 200000) * 500),
'SERIES',
IF(RAND(rn + 300000) < 0.9, 'PUBLIC', 'PRIVATE'),
IF(RAND(rn + 400000) < 0.9, 'COMPLETED', 'INIT'),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND(rn + 500000) * 365) DAY),
NOW(),
'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_series/10000.0)) nums
WHERE rn <= @v_series;
SET @sm_start = LAST_INSERT_ID();
INSERT INTO series (media_id, actors, created_date, modified_date, status)
SELECT
@sm_start + rn - 1,
CONCAT('배우', FLOOR(RAND(rn) * 50) + 1, ', 배우', FLOOR(RAND(rn + 100000) * 50) + 51),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND(rn + 500000) * 365) DAY),
NOW(),
'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_series/10000.0)) nums
WHERE rn <= @v_series;
SET @s_start = LAST_INSERT_ID();
SET @s_count = @v_series;
SELECT CONCAT('[4/16] media(SERIES) + series: ', @v_series) AS progress;
-- =============================================
-- 5. MEDIA (CONTENTS) + CONTENTS
-- =============================================
INSERT INTO media (uploader_id, title, description, poster_url, thumbnail_url, bookmark_count, likes_count, media_type, public_status, media_status, created_date, modified_date, status)
SELECT
@up_start + FLOOR(RAND(rn + 600000) * @up_count),
CONCAT('콘텐츠 ', rn),
CONCAT('콘텐츠 ', rn, '의 설명입니다.'),
CONCAT('/posters/contents_', rn, '.jpg'),
CONCAT('/thumbnails/contents_', rn, '.jpg'),
FLOOR(RAND(rn + 700000) * 300),
FLOOR(RAND(rn + 800000) * 800),
'CONTENTS',
IF(RAND(rn + 900000) < 0.9, 'PUBLIC', 'PRIVATE'),
IF(RAND(rn + 1000000) < 0.9, 'COMPLETED', 'INIT'),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND(rn + 1100000) * 365) DAY),
NOW(),
'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_contents/10000.0)) nums
WHERE rn <= @v_contents;
SET @cm_start = LAST_INSERT_ID();
INSERT INTO contents (media_id, series_id, actors, duration, video_size, origin_url, master_playlist_url, created_date, modified_date, status)
SELECT
@cm_start + rn - 1,
IF(RAND(rn + 1200000) < 0.7, @s_start + FLOOR(RAND(rn + 1300000) * @s_count), NULL),
CONCAT('배우', FLOOR(RAND(rn + 1400000) * 50) + 1, ', 배우', FLOOR(RAND(rn + 1500000) * 50) + 51),
IF(RAND(rn + 1600000) < 0.35,
FLOOR(5400 + RAND(rn + 1700000) * 1800),
FLOOR(1800 + RAND(rn + 1800000) * 1800)),
FLOOR(500 + RAND(rn + 1900000) * 2500),
CONCAT('/videos/contents_', rn, '.mp4'),
IF(RAND(rn + 1000000) < 0.9, CONCAT('/hls/contents_', rn, '/master.m3u8'), NULL),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND(rn + 1100000) * 365) DAY),
NOW(),
'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_contents/10000.0)) nums
WHERE rn <= @v_contents;
SET @c_start = LAST_INSERT_ID();
SET @c_count = @v_contents;
SELECT CONCAT('[5/16] media(CONTENTS) + contents: ', @v_contents) AS progress;
-- =============================================
-- 6. MEDIA (SHORT_FORM) + SHORT_FORM
-- =============================================
INSERT INTO media (uploader_id, title, description, poster_url, thumbnail_url, bookmark_count, likes_count, media_type, public_status, media_status, created_date, modified_date, status)
SELECT
@up_start + FLOOR(RAND(rn + 2000000) * @up_count),
CONCAT('숏폼 ', rn),
CONCAT('숏폼 ', rn, '의 설명입니다.'),
CONCAT('/posters/short_', rn, '.jpg'),
NULL,
FLOOR(RAND(rn + 2100000) * 100),
FLOOR(RAND(rn + 2200000) * 300),
'SHORT_FORM',
IF(RAND(rn + 2300000) < 0.9, 'PUBLIC', 'PRIVATE'),
IF(RAND(rn + 2400000) < 0.9, 'COMPLETED', 'INIT'),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND(rn + 2500000) * 365) DAY),
NOW(),
'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_sf/10000.0)) nums
WHERE rn <= @v_sf;
SET @sfm_start = LAST_INSERT_ID();
INSERT INTO short_form (media_id, series_id, contents_id, duration, video_size, origin_url, master_playlist_url, created_date, modified_date, status)
SELECT
@sfm_start + rn - 1,
NULL,
IF(RAND(rn + 2600000) < 0.5, @c_start + FLOOR(RAND(rn + 2700000) * @c_count), NULL),
FLOOR(15 + RAND(rn + 2800000) * 45),
FLOOR(10 + RAND(rn + 2900000) * 100),
CONCAT('/videos/short_', rn, '.mp4'),
IF(RAND(rn + 2400000) < 0.9, CONCAT('/hls/short_', rn, '/master.m3u8'), NULL),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND(rn + 2500000) * 365) DAY),
NOW(),
'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_sf/10000.0)) nums
WHERE rn <= @v_sf;
SET @sf_start = LAST_INSERT_ID();
SET @sf_count = @v_sf;
-- Track overall media range
SET @media_start = @sm_start;
SET @media_count = @v_media;
SELECT CONCAT('[6/16] media(SHORT_FORM) + short_form: ', @v_sf) AS progress;
-- =============================================
-- 7. MEDIA_TAG (3 per media, offsets 0/9/19 coprime to 28)
-- =============================================
INSERT INTO media_tag (tag_id, media_id, created_date, modified_date, status)
SELECT
((nums.rn - 1 + t.offset) % 28) + 1,
@media_start + nums.rn - 1,
NOW(), NOW(), 'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_media/10000.0)) nums
CROSS JOIN (SELECT 0 AS offset UNION ALL SELECT 9 UNION ALL SELECT 19) t
WHERE nums.rn <= @v_media;
SELECT CONCAT('[7/16] media_tag: ', @v_media * 3) AS progress;
-- =============================================
-- 8. MEDIA_MOOD_TAG (2 per media, offsets 0/15 coprime to 31, INSERT IGNORE for UK)
-- =============================================
INSERT IGNORE INTO media_mood_tag (media_id, mood_tag_id, priority, created_date, modified_date, status)
SELECT
@media_start + nums.rn - 1,
((nums.rn - 1 + t.offset) % 31) + 1,
t.pri,
NOW(), NOW(), 'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_media/10000.0)) nums
CROSS JOIN (SELECT 0 AS offset, 0 AS pri UNION ALL SELECT 15, 1) t
WHERE nums.rn <= @v_media;
SELECT CONCAT('[8/16] media_mood_tag: ~', @v_media * 2) AS progress;
-- =============================================
-- 9. MEDIA_METRICS (1:1 with media)
-- =============================================
INSERT INTO media_metrics (media_id, popularity, immersion, mania, recency, re_watch, batch_updated_at, created_date, modified_date, status)
SELECT
@media_start + rn - 1,
ROUND(RAND(rn) * 100, 2),
ROUND(RAND(rn + 100000) * 100, 2),
ROUND(RAND(rn + 200000) * 100, 2),
ROUND(RAND(rn + 300000) * 100, 2),
ROUND(RAND(rn + 400000) * 100, 2),
NOW(),
NOW(), NOW(), 'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_media/10000.0)) nums
WHERE rn <= @v_media;
SELECT CONCAT('[9/16] media_metrics: ', @v_media) AS progress;
-- =============================================
-- 10. BOOKMARK (Fill until target, avoid duplicates)
-- =============================================
SET @current_count = 0;
bookmark_loop: WHILE @current_count < @v_bookmark DO
SET @needed = @v_bookmark - @current_count;
INSERT IGNORE INTO bookmark (member_id, media_id, created_date, modified_date, status)
SELECT t.m_id, t.med_id, DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 180) DAY), NOW(), 'ACTIVE'
FROM (
SELECT
@m_start + FLOOR(RAND() * @v_member) AS m_id,
@media_start + FLOOR(POW(RAND(), 2) * @media_count) AS med_id
FROM _seed_seq LIMIT 2000
) t
LEFT JOIN bookmark b ON t.m_id = b.member_id AND t.med_id = b.media_id
WHERE b.id IS NULL
GROUP BY t.m_id, t.med_id
LIMIT 2000;
SELECT COUNT(*) INTO @current_count FROM bookmark;
END WHILE bookmark_loop;
SELECT CONCAT('[10/16] bookmark: ', @v_bookmark) AS progress;
-- =============================================
-- 11. LIKES (Fill until target, avoid duplicates)
-- =============================================
SET @current_count = 0;
likes_loop: WHILE @current_count < @v_likes DO
SET @needed = @v_likes - @current_count;
INSERT IGNORE INTO likes (member_id, media_id, created_date, modified_date, status)
SELECT t.m_id, t.med_id, DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 180) DAY), NOW(), 'ACTIVE'
FROM (
SELECT
@m_start + FLOOR(RAND() * @v_member) AS m_id,
@media_start + FLOOR(POW(RAND(), 2) * @media_count) AS med_id
FROM _seed_seq LIMIT 2000
) t
LEFT JOIN likes l ON t.m_id = l.member_id AND t.med_id = l.media_id
WHERE l.id IS NULL
GROUP BY t.m_id, t.med_id
LIMIT 2000;
SELECT COUNT(*) INTO @current_count FROM likes;
END WHILE likes_loop;
SELECT CONCAT('[11/16] likes: ', @v_likes) AS progress;
-- =============================================
-- 12. COMMENT (contents only)
-- =============================================
INSERT INTO comment (member_id, contents_id, content, is_spoiler, created_date, modified_date, status)
SELECT
@m_start + FLOOR(RAND(rn + 6000000) * @v_member),
@c_start + FLOOR(RAND(rn + 7000000) * @c_count),
CONCAT('테스트 댓글 ', rn),
IF(RAND(rn + 8000000) < 0.1, TRUE, FALSE),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND(rn + 9000000) * 180) DAY),
NOW(),
'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_comment/10000.0)) nums
WHERE rn <= @v_comment;
SELECT CONCAT('[12/16] comment: ', @v_comment) AS progress;
-- =============================================
-- 13. WATCH_HISTORY (Fill until target, avoid duplicates)
-- =============================================
SET @current_count = 0;
WHILE @current_count < @v_watch DO
SET @needed = @v_watch - @current_count;
INSERT IGNORE INTO watch_history (member_id, contents_id, last_watched_at, re_watch_count, is_used_for_ml, created_date, modified_date, status)
SELECT
@m_start + FLOOR(RAND() * @v_member),
@c_start + FLOOR(RAND() * @c_count),
DATE_SUB(NOW(), INTERVAL FLOOR(POW(RAND(), 2) * 90) DAY),
CASE WHEN RAND() < 0.80 THEN 0 WHEN RAND() < 0.95 THEN 1 ELSE FLOOR(2 + RAND() * 3) END,
FALSE,
DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 365) DAY),
NOW(), 'ACTIVE'
FROM _seed_seq LIMIT 5000;
SELECT COUNT(*) INTO @current_count FROM watch_history;
END WHILE;
SELECT CONCAT('[13/16] watch_history: ', @v_watch) AS progress;
-- =============================================
-- 14. PLAYBACK (Fill until target, avoid duplicates)
-- =============================================
SET @current_count = 0;
WHILE @current_count < @v_playback DO
SET @needed = @v_playback - @current_count;
INSERT IGNORE INTO playback (member_id, contents_id, position_sec, created_date, modified_date, status)
SELECT
@m_start + FLOOR(RAND() * @v_member),
@c_start + FLOOR(RAND() * @c_count),
FLOOR(RAND() * 7200),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 90) DAY),
NOW(), 'ACTIVE'
FROM _seed_seq LIMIT 5000;
SELECT COUNT(*) INTO @current_count FROM playback;
END WHILE;
SELECT CONCAT('[14/16] playback: ', @v_playback) AS progress;
-- =============================================
-- 15. CLICK_EVENT
-- =============================================
INSERT INTO click_event (member_id, short_form_id, click_at, click_type, created_date, modified_date, status)
SELECT
@m_start + FLOOR(RAND(rn + 20000000) * @v_member),
@sf_start + FLOOR(RAND(rn + 21000000) * @sf_count),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND(rn + 22000000) * 90) DAY),
IF(RAND(rn + 23000000) < 0.7, 'SHORT_CLICK', 'CTA_CLICK'),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND(rn + 22000000) * 90) DAY),
NOW(),
'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_click/10000.0)) nums
WHERE rn <= @v_click;
SELECT CONCAT('[15/16] click_event: ', @v_click) AS progress;
-- =============================================
-- 16. MEMBER_MOOD_REFRESH (50% of members)
-- =============================================
SET @v_mood_refresh = FLOOR(@v_member * 0.5);
INSERT INTO member_mood_refresh (member_id, image_id, subtitle, recommended_media_ids, is_hidden, created_date, modified_date, status)
SELECT
@m_start + rn - 1,
FLOOR(RAND(rn + 24000000) * 10) + 1,
CONCAT('오늘의 무드 ', rn),
JSON_ARRAY(
@media_start + FLOOR(RAND(rn + 25000000) * @media_count),
@media_start + FLOOR(RAND(rn + 25100000) * @media_count),
@media_start + FLOOR(RAND(rn + 25200000) * @media_count),
@media_start + FLOOR(RAND(rn + 25300000) * @media_count),
@media_start + FLOOR(RAND(rn + 25400000) * @media_count)
),
IF(RAND(rn + 26000000) < 0.2, TRUE, FALSE),
NOW(), NOW(), 'ACTIVE'
FROM (SELECT ((a.n-1)*10000+b.n) rn FROM _seed_seq a CROSS JOIN _seed_seq b WHERE a.n <= CEIL(@v_mood_refresh/10000.0)) nums
WHERE rn <= @v_mood_refresh;
SELECT CONCAT('[16/16] member_mood_refresh: ', @v_mood_refresh) AS progress;
-- =============================================
-- 17. SYNC DE-NORMALIZED COUNTS
-- =============================================
UPDATE media m
SET
m.likes_count = (SELECT COUNT(*) FROM likes l WHERE l.media_id = m.id AND l.status = 'ACTIVE'),
m.bookmark_count = (SELECT COUNT(*) FROM bookmark b WHERE b.media_id = m.id AND b.status = 'ACTIVE');
SELECT '[17/17] Sync de-normalized counts: media(likes_count, bookmark_count) updated' AS progress;
-- =============================================
-- CLEANUP
-- =============================================
SET FOREIGN_KEY_CHECKS = 1;
SET UNIQUE_CHECKS = 1;
DROP TABLE IF EXISTS _seed_seq;
SELECT CONCAT('Seed completed! preset=', p_preset,
', elapsed=', TIMESTAMPDIFF(SECOND, @start_time, NOW()), 's',
', members=', @v_member, ', media=', @v_media,
', bookmarks=', @v_bookmark, ', watch_history=', @v_watch) AS result;
END //
DELIMITER ;
Category/Tag 스크립트
-- =============================================
-- OTT 서비스 카테고리/태그 고정 메타데이터
-- 사용법: mysql -u ott -p ott < scripts/seed-metadata.sql
-- =============================================
INSERT INTO category (id, name, created_date, modified_date, status) VALUES
(1, '장르', NOW(), NOW(), 'ACTIVE'),
(2, '분위기', NOW(), NOW(), 'ACTIVE'),
(3, '시청상황', NOW(), NOW(), 'ACTIVE'),
(4, '테마', NOW(), NOW(), 'ACTIVE')
ON DUPLICATE KEY UPDATE name = VALUES(name), modified_date = NOW();
INSERT INTO tag (id, category_id, name, created_date, modified_date, status) VALUES
-- 장르 (category_id = 1)
(1, 1, '액션', NOW(), NOW(), 'ACTIVE'),
(2, 1, '로맨스', NOW(), NOW(), 'ACTIVE'),
(3, 1, 'SF', NOW(), NOW(), 'ACTIVE'),
(4, 1, '스릴러', NOW(), NOW(), 'ACTIVE'),
(5, 1, '코미디', NOW(), NOW(), 'ACTIVE'),
(6, 1, '드라마', NOW(), NOW(), 'ACTIVE'),
(7, 1, '호러', NOW(), NOW(), 'ACTIVE'),
(8, 1, '판타지', NOW(), NOW(), 'ACTIVE'),
(9, 1, '다큐멘터리', NOW(), NOW(), 'ACTIVE'),
(10, 1, '애니메이션', NOW(), NOW(), 'ACTIVE'),
-- 분위기 (category_id = 2)
(11, 2, '긴장감', NOW(), NOW(), 'ACTIVE'),
(12, 2, '따뜻한', NOW(), NOW(), 'ACTIVE'),
(13, 2, '유쾌한', NOW(), NOW(), 'ACTIVE'),
(14, 2, '어두운', NOW(), NOW(), 'ACTIVE'),
(15, 2, '감동적인', NOW(), NOW(), 'ACTIVE'),
-- 시청상황 (category_id = 3)
(16, 3, '혼자볼때', NOW(), NOW(), 'ACTIVE'),
(17, 3, '연인과', NOW(), NOW(), 'ACTIVE'),
(18, 3, '가족과', NOW(), NOW(), 'ACTIVE'),
(19, 3, '심심할때', NOW(), NOW(), 'ACTIVE'),
(20, 3, '잠들기전', NOW(), NOW(), 'ACTIVE'),
-- 테마 (category_id = 4)
(21, 4, '성장', NOW(), NOW(), 'ACTIVE'),
(22, 4, '복수', NOW(), NOW(), 'ACTIVE'),
(23, 4, '우정', NOW(), NOW(), 'ACTIVE'),
(24, 4, '가족', NOW(), NOW(), 'ACTIVE'),
(25, 4, '사랑', NOW(), NOW(), 'ACTIVE'),
(26, 4, '생존', NOW(), NOW(), 'ACTIVE'),
(27, 4, '범죄', NOW(), NOW(), 'ACTIVE'),
(28, 4, '일상', NOW(), NOW(), 'ACTIVE')
ON DUPLICATE KEY UPDATE category_id = VALUES(category_id), name = VALUES(name), modified_date = NOW();
SELECT CONCAT('Metadata seeded: ', (SELECT COUNT(*) FROM category), ' categories, ', (SELECT COUNT(*) FROM tag), ' tags') AS result;
데이터 삭제 스크립트
-- =============================================
-- 테스트 데이터 전체 삭제 (메타데이터 유지)
-- 사용법: mysql -u ott -p ott < scripts/clean-data.sql
-- =============================================
SET FOREIGN_KEY_CHECKS = 0;
TRUNCATE TABLE member_mood_refresh;
TRUNCATE TABLE click_event;
TRUNCATE TABLE playback;
TRUNCATE TABLE watch_history;
TRUNCATE TABLE comment;
TRUNCATE TABLE likes;
TRUNCATE TABLE bookmark;
TRUNCATE TABLE media_metrics;
TRUNCATE TABLE media_mood_tag;
TRUNCATE TABLE media_tag;
TRUNCATE TABLE short_form;
TRUNCATE TABLE contents;
TRUNCATE TABLE series;
TRUNCATE TABLE media;
TRUNCATE TABLE preferred_tag;
TRUNCATE TABLE member_radar_preference;
TRUNCATE TABLE member;
-- 유지: category, tag, mood_category, mood_tag
SET FOREIGN_KEY_CHECKS = 1;
SELECT 'Clean completed. Metadata tables (category, tag, mood_category, mood_tag) preserved.' AS result;
테스트 시나리오 작성
가장 접근이 잦고, 호출되는 API가 많은 홈 화면에 대한 테스트 시나리오를 작성했습니다.
총 4개의 API가 호출되며, 그 중 한 개의 API는 상황에 따라 세 가지로 분류되어 6개의 API를 시나리오에 포함시켰습니다.
1 iteration == 사용자가 홈 화면에 진입했을 때 호출되는 API 묶음으로 설정했습니다.
| # | API | 설명 | 예상 부하 특성 |
| 1 | GET /playlists/trending | 인기 차트 | 가벼움 (전체 사용자 동일, 캐싱 후보) |
| 2 | GET /playlists/recommend | OO님이 좋아할만한 | 무거움 (사용자별 동적 CASE WHEN 쿼리) |
| 3 | GET /playlists/tags/top?index=0 | 선호태그 1순위 | 중간 (사용자별 태그 기반 조회) |
| 4 | GET /playlists/tags/top?index=1 | 선호태그 2순위 | 중간 |
| 5 | GET /playlists/tags/top?index=2 | 선호태그 3순위 | 중간 |
| 6 | GET /playlists/history | 시청이력 | 무거움 (조건부 JOIN + GROUP BY) |
K6 스크립트
import http from 'k6/http';
import { check, group, sleep } from 'k6';
import { BASE_URL, THRESHOLDS, STAGES } from '../config.js';
import { getAuthHeaders } from '../helpers/auth.js';
// -------------------------------------------------------
// 시나리오: 홈 화면 진입
//
// 사용자가 홈 화면에 진입하면 프론트엔드가 6개 API를 호출한다.
// 이 시나리오는 1 iteration = 6 HTTP requests로 실제 동작을 시뮬레이션.
//
// 포함 API:
// 1. GET /playlists/trending - 인기 차트 (북마크 수 기준 인기순)
// 2. GET /playlists/recommend - OO님이 좋아할만한 (태그 가중치 기반 추천)
// 3. GET /playlists/tags/top?index=0 - 선호태그 1순위 콘텐츠
// 4. GET /playlists/tags/top?index=1 - 선호태그 2순위 콘텐츠
// 5. GET /playlists/tags/top?index=2 - 선호태그 3순위 콘텐츠
// 6. GET /playlists/history - 시청이력 (최근 시청 영상 목록)
//
// 사용법:
// k6 run --env LOAD=smoke k6/scenarios/home-screen.js # 동작 확인
// k6 run --env LOAD=vu100 k6/scenarios/home-screen.js # VU 100
// k6 run --env LOAD=vu1000 k6/scenarios/home-screen.js # VU 1,000
//
// # Grafana 모니터링 연동
// k6 run --env LOAD=vu1000 --out influxdb=http://localhost:8086/k6 k6/scenarios/home-screen.js
//
// # 결과 JSON 저장 (Before/After 비교용)
// k6 run --env LOAD=vu1000 --out json=k6/results/before/home-screen-vu1000.json k6/scenarios/home-screen.js
//
// 주요 지표 해석:
// http_req_duration : 개별 API 응답 시간
// http_req_duration{name:XXX} : API별 응답 시간 (tag로 분리)
// group_duration : 홈 화면 전체 로드 시간 (6 request 묶음)
// http_reqs : 초당 처리량 (RPS)
// http_req_failed : 에러율 (1% 미만이어야 정상)
//
// Before/After 비교 포인트:
// - recommend의 p95가 가장 높을 것으로 예상 (동적 CASE WHEN 쿼리)
// - history도 조건부 JOIN+GROUP BY로 높을 수 있음
// - 개선 후 동일 VU로 재측정하여 개선율(%) 산출
// -------------------------------------------------------
export const options = {
stages: STAGES[__ENV.LOAD || 'vu100'],
thresholds: {
...THRESHOLDS,
// API별 임계값 (tag name으로 분리 측정)
// Before에서 이 기준을 넘기는 API = 개선 대상
'http_req_duration{name:trending}': ['p(95)<500'],
'http_req_duration{name:recommend}': ['p(95)<500'],
'http_req_duration{name:tags_top_0}': ['p(95)<500'],
'http_req_duration{name:tags_top_1}': ['p(95)<500'],
'http_req_duration{name:tags_top_2}': ['p(95)<500'],
'http_req_duration{name:history}': ['p(95)<500'],
},
};
export default function () {
const params = getAuthHeaders();
// -------------------------------------------------------
// group: 홈 화면 전체를 하나의 묶음으로 측정
// → group_duration 지표로 "홈 진입 1회 총 소요 시간" 확인 가능
// → Grafana에서 group별 차트로 전체 로드 시간 추이 확인
// -------------------------------------------------------
group('홈 화면 진입', function () {
// 1. 인기 차트
// 북마크 수 기준 인기 콘텐츠. 모든 사용자 동일 결과 → 캐싱 후보.
const trending = http.get(
`${BASE_URL}/playlists/trending?page=0&size=20`,
Object.assign({}, params, { tags: { name: 'trending' } })
);
check(trending, {
'[trending] status 200': (r) => r.status === 200,
});
// 2. OO님이 좋아할만한 (추천 플레이리스트)
// 사용자별 선호 태그 가중치 기반. 동적 CASE WHEN 쿼리 → 가장 무거울 것으로 예상.
const recommend = http.get(
`${BASE_URL}/playlists/recommend?page=0&size=20`,
Object.assign({}, params, { tags: { name: 'recommend' } })
);
check(recommend, {
'[recommend] status 200': (r) => r.status === 200,
});
// 3~5. 선호태그 순위별 top3 (index 0, 1, 2)
// 사용자의 상위 3개 선호 태그별 콘텐츠 목록.
// 홈 화면에서 3번 연속 호출됨.
for (let i = 0; i < 3; i++) {
const tagsTop = http.get(
`${BASE_URL}/playlists/tags/top?index=${i}&page=0&size=20`,
Object.assign({}, params, { tags: { name: `tags_top_${i}` } })
);
check(tagsTop, {
[`[tags_top_${i}] status 200`]: (r) => r.status === 200,
});
}
// 6. 시청이력 (최근 시청 영상 목록)
// 조건부 JOIN + GROUP BY + MAX 서브쿼리 → 복잡 쿼리 개선 후보.
const history = http.get(
`${BASE_URL}/playlists/history?page=0&size=20`,
Object.assign({}, params, { tags: { name: 'history' } })
);
check(history, {
'[history] status 200': (r) => r.status === 200,
});
});
// think time: 사용자가 홈 화면 결과를 보는 시간 (1초)
// 제거하면 요청을 쉬지 않고 연속으로 쏨 → 순수 서버 처리 한계 측정
sleep(1);
}
JWT 토큰 발급
해당 프로젝트는 카카오 로그인만을 제공하고, Spring Security + JWT를 사용했기 때문에, 요청 시 토큰이 필요했습니다.
'공유 토큰 사용 → 1명 데이터만 반복 조회 → 캐시 히트 비정상 → 결과 왜곡'이라는 문제가 있었기에 각 VU는 다른 사용자의 JWT를 사용하도록 구성했습니다.
| VU 수 | 토큰 1000개 기준 | 상태 |
| 100 | 100명 각각 고유 | 이상적 |
| 500 | 500명 각각 고유 | 이상적 |
| 1,000 | 1:1 매핑 | 이상적 |
| 5,000 | 1명당 5 VU 공유 | 허용 |
| 10,000 | 1명당 10 VU 공유 | 허용 |
부하 테스트 자동화
매번 수동으로 데이터 규모별로, VU 프리셋별로 테스트를 진행하기엔 번거로움이 많았습니다. 그래서 테스트를 원하는 데이터 규모와 프리셋을 지정하면 자동으로 K6 테스트를 수행하고 그 결과를 JSON으로 저장하는 자동화 환경을 구성했습니다. 또한, 개선 후에도 비교하기 수월하도록 저장된 결과를 MD 문서로 보기 쉽게 정리하는 스크립트를 작성했습니다.
'DB 초기화 -> 데이터 생성 -> VU별 테스트 실행 -> 부하 테스트 결과 JSON 저장' 구조를 자동으로 반복하기에, 필요할 때마다 한 번만 실행시키고, 이를 바탕으로 결과 요약 스크립트를 실행시키면 .md 파일로 변환시킬 수 있습니다.
[파일 구조]
k6/
├── config.js ← 공통 설정 (URL, 임계값, VU 단계)
├── helpers/auth.js ← VU별 개별 JWT 토큰 관리
├── data/tokens.json ← 시드 사용자 1,000명 JWT (gitignore)
├── scenarios/home-screen.js ← 홈 화면 시나리오 (6 API, 6 requests)
├── docker-compose.monitoring.yml ← InfluxDB (k6 결과 저장)
├── run-all-before.ps1 ← 일괄 측정 (PowerShell)
├── run-all-before.sh ← 일괄 측정 (Bash)
├── parse-results.ps1 ← 결과 → md 보고서 (PowerShell)
├── parse-results.sh ← 결과 → md 보고서 (Bash)
└── results/ ← 측정 결과
├── before/{seed}/summary-{vu}.json
├── before/report.md
├── after/{seed}/summary-{vu}.json
└── after/report.md
[결과 요약 예시]

로깅
p6spy
API에서 발생하는 쿼리를 파악하기 위해 p6spy를 사용했습니다.
K6 부하 테스트로 병목 지점을 파악하고, 해당 API를 실행시켜 쿼리가 몇 번 나가고 얼마나 걸리는지, 어떤 쿼리가 나가는지를 확인하기 위함입니다.
2026-04-28T18:57:06.791+09:00 INFO 38132 --- [nio-8080-exec-6] p6spy : [STATEMENT] | 1 ms |
select
m1_0.id,
m1_0.bookmark_count,
m1_0.created_date,
...
from
media m1_0
where
m1_0.id=24508
AOP
p6spy와 더불어 Controller, Service 등 계층별로 소요되는 시간을 함께 파악하고자 AOP를 적용했습니다.
INFO 38132 --- [nio-8080-exec-1] c.o.c.web.aop.PerformanceLoggingAspect : [SERVICE] PlaylistStrategyService.getPlaylists() 690ms
INFO 38132 --- [nio-8080-exec-1] c.o.c.web.aop.PerformanceLoggingAspect : [CONTROLLER] PlaylistController.getHistoryPlaylists() 792ms
당장 쓰이진 않지만, 함수 단위로 호출 횟수와 소요 시간을 파악할 수 있고, 이를 기반으로 Grafana에서 확인 가능합니다.
모니터링
Prometheus와 Grafana로 지표를 확인하고 있습니다.
기본적인 JVM 리소스와 DB 커넥션, HTTP 통계를 확인할 수 있습니다.


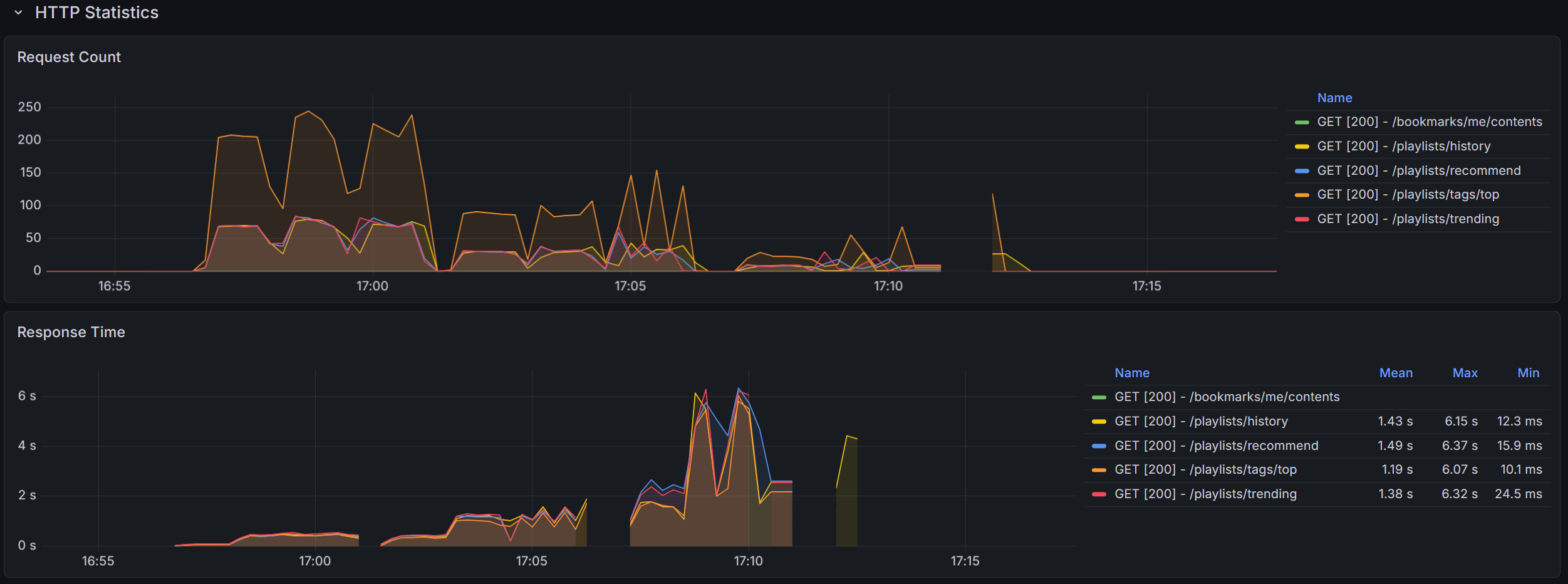
위 기록은 데이터 규모 small, medium, large / VU 100, 500, 1000으로 3x3 테스트를 진행한 결과입니다.
'Project' 카테고리의 다른 글
| [O+T] 영상 이어보기 처리량 개선하기 (0) | 2026.05.13 |
|---|---|
| [O+T] 홈 화면 인기 플레이리스트 API 개선하기 (0) | 2026.05.09 |
| 다중 기기 환경에서의 푸시 알림 (0) | 2025.04.03 |
| 상황별 조회수 성능을 위해 고려할 수 있는 것 (0) | 2025.04.01 |
| 조회수 카운팅 시 동시성 문제 (0) | 2025.03.23 |