

💡이 글은 파일 업로드 방법에 대해 살펴본 내용입니다. Spring boot를 사용할 때, 파일 업로드 진행 과정과 방법들을 살펴보고 선택합니다. 기존 파일 업로드 코드 개선부터, 새로운 방식 도입까지의 과정을 작성했습니다
이번 글에서는 오랜만에 살펴보는 코드이므로 간단한 리팩토링 내용에 대해 적어보겠습니다. 여러 주제가 있는데, 팀원이 작성했던 S3에 파일 업로드하는 로직에 대해 살펴보겠습니다. 동작 방식을 알아보고, 다음 글에서 여러 방식을 적용한 개선 사례를 이야기 해보겠습니다.
0. 전시로그 파일 업로드 기본 로직 변경
기존 방식
흐름도
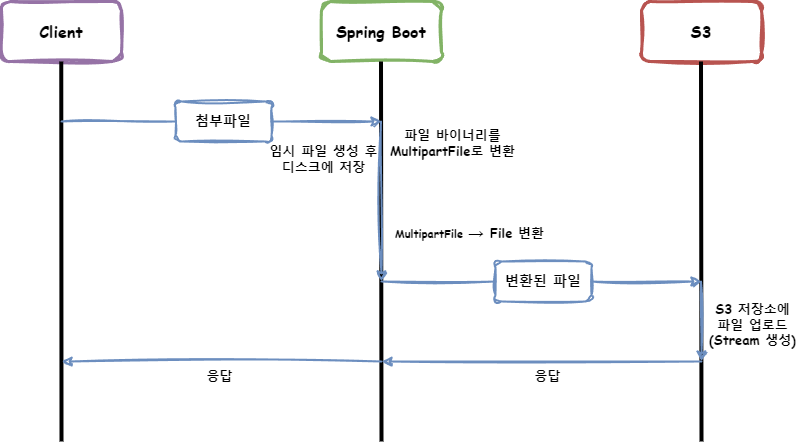
1. Client가 첨부 파일을 Spring Boot 서버로 전송합니다.
2. 일정 용량 초과 시 임시 파일을 생성하고, Disk에 저장한 후, 파일 바이너리를 MultipartFile로 변환합니다.
3. Service Layer에서 MultipartFile -> File로 변환합니다.
4. S3 저장소로 변환된 파일을 전송합니다.
5. AWS SDK가 내부에서 FileInputStream을 여러서 파일을 저장합니다.
내부

1. file-size-threshold 설정 값 초과 시 톰캣은 디스크에 임시 파일을 생성합니다.
2. Service Layer에서 변환한 File을 S3로 전송합니다.
코드
public String upload(MultipartFile multipartFile, String dirName) throws IOException {
File uploadFile = convert(multipartFile)
.orElseThrow(() -> new IllegalArgumentException("MultipartFile -> File 전환 실패"));
return upload(uploadFile, dirName);
}
private Optional<File> convert(MultipartFile file) throws IOException {
File convertFile = new File(file.getOriginalFilename());
removeNewFile(convertFile);
if (convertFile.createNewFile()) {
try (FileOutputStream fos = new FileOutputStream(convertFile)) {
fos.write(file.getBytes());
}
return Optional.of(convertFile);
}
return Optional.empty();
}
private String upload(File uploadFile, String dirName) {
String fileName = dirName + "/"
+ UUID.randomUUID().toString()
+ "_"
+ uploadFile.getName();
String uploadImageUrl = putS3(uploadFile, fileName);
removeNewFile(uploadFile); // 로컬에 생성된 File 삭제 (MultipartFile -> File 전환 하며 로컬에 파일 생성됨)
return uploadImageUrl; // 업로드된 파일의 S3 URL 주소 반환
}기존 로직은 MultipartFile -> File로 변환하여 내부에 저장한 후, S3에 해당 파일을 전송합니다.
이 방법은 스프링에서 제공하는 MultipartFile 변환 시 사용하는 InputStream을 사용하지 않고, 디스크에 파일을 생성합니다. 두 가지 문제를 발견할 수 있었는데, File 생성으로 인한 불필요한 디스크 사용과, file.getBytes()로 전체 바이너리 파일을 읽는 메모리 낭비입니다.
저는 File 객체를 생성하지 않고, MultipartFile 변환 시 사용한 InputStream을 사용하여 S3에 넘겨주는 방식으로 로직을 변경하여 개선하기로 했습니다.
개선 후 방식
흐름도

1. Client가 첨부 파일을 Spring Boot 서버로 전송합니다.
2. 일정 용량 초과 시 임시 파일을 생성하고, Disk에 저장한 후, 파일 바이너리를 MultipartFile로 변환합니다.
3. Client로부터 첨부 파일 수신 시 사용된 InputStream을 사용하여 S3에 전송합니다.
내부

file-size-threshold 설정 값 초과 시 톰캣은 디스크에 임시 파일을 생성합니다.
public String multipartFileUpload(MultipartFile file, String dirName) {
if (file.isEmpty())
return null;
String originalFileName = file.getOriginalFilename();
String saveFileName = S3FileUtil.createSaveFileName(originalFileName); // uuid . ext
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentLength(file.getSize());
metadata.setContentType(file.getContentType());
String filePath = dirName + "/" + saveFileName;
try (InputStream inputStream = file.getInputStream()) {
// S3에 업로드
amazonS3.putObject(new PutObjectRequest(bucket, filePath, inputStream, metadata));
} catch (IOException e) {
rollbackIfExists(bucket, filePath);
throw new RuntimeException("파일 업로드에 실패했습니다.", e);
}
return S3FileUtil.getFullPath(bucket, filePath);
}
1. MultipartFile이 가진 InputStream(이미 Spring이 열어준 스트림)을 직접 S3에 putObject로 넘기도록 변경했습니다.
2. 따라서, 추가로 로컬 파일을 만드는 과정이 전혀 없고, 업로드 프로세스 중에 우리가 직접 만드는 임시 파일이 없으니, 로컬 디스크 I/O가 훨씬 적습니다.
3. 업로드 중 예외 발생 시 이미 파일이 올라갔다면, 해당 파일을 삭제하도록 롤백 과정을 추가했습니다
[참고 자료]
https://ksh-dev.tistory.com/55
'Project' 카테고리의 다른 글
| Bulk 연산으로 Write 작업 개선하기 (0) | 2025.03.13 |
|---|---|
| 외부 API 호출 시 고려할 것 (0) | 2025.03.10 |
| 배치 프로세스 리팩토링 (0) | 2025.03.03 |
| Swagger 코드 분리, Http Status (0) | 2025.02.28 |
| 효과적인 파일 업로드 방법 (0) | 2025.01.19 |