

💡이번 글에서는 파일 업로드 방식에 대해 알아본 내용을 소개합니다. Spring에서 흔히 사용되는 3가지 방법을 다룹니다. 또한, 대용량 파일 전송 시 사용하면 좋은 방법에 대해 알아봅니다.
Multipart와 Octet-Stream 방식, S3의 Pre-Signed Url 방식과 대용량 파일 업로드를 위한 AWS Multipart를 사용하여 파일 업로드하는 방식이 소개됩니다.
기술 블로그 서비스를 만들며 파일 업로드 부분에서의 개선점이 생각나 리팩토링을 진행하기로 했습니다.
기술 블로그 특성 상 이미지 파일이 주로 올라오지만, 제한은 딱히 두지 않았습니다. 처음 개발할 때는 이미지라고 가정하고 개발했지만, 요구사항을 넓혀 다양한 용량의 파일까지 업로드가 가능하다는 전제 하에 파일 업로드 방식을 개선하고자 합니다.
이미지 저장소로 AWS S3를 사용하고 있으며, S3를 사용할 때에만 가능한 방법도 소개됩니다.
1. Octet-Stream 방식
2. Multipart 방식
3. Pre-Signed Url 방식
위 세 가지와 대용량 파일 업로드 시 청크 단위로 분리하여 보내는 방법을 소개합니다.
1. 파일 업로드 방식
먼저, 파일 업로드 방식으로 구분할 수 있습니다.
크게, Spring Boot 서버를 경유하는 방법과, 클라이언트가 S3에 직접 업로드하는 방법이 있습니다.
Spring Boot 서버 경유
클라이언트 -> 서버 -> S3 순서로 업로드가 이뤄지며, 서버가 파일 업로드를 위한 중개 역할을 하게 됩니다.
대표적으로 Multipart와 Octet-Stream 두 가지 방식이 사용됩니다.
1) Multipart/form-data
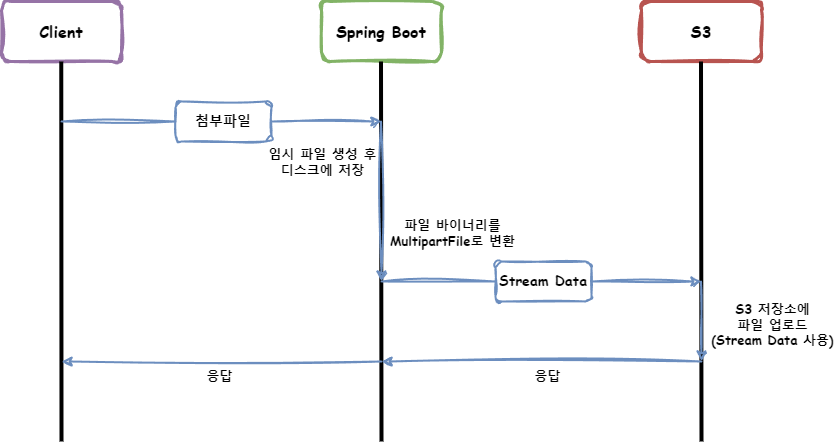
먼저, Multipart 업로드 방식은 Spring에서 제공하는 MultipartFile 인터페이스를 이용합니다. 파일을 보낼 때, Multipar/form-data 타입으로 보내며, 다른 데이터와 함께 전송할 수 있다는 특징이 있습니다.
이 방식은 MultipartFile 인터페이스에 이미 정의된 내용들로 인해 높은 편의성을 가지고 있습니다.
아래와 같이 .yml 파일에서 설정을 통해 스펙을 상세하게 정할 수 있습니다.
spring:
servlet:
multipart:
enabled: true # 멀티파트 업로드 지원여부
file-size-threshold: 0B # 파일을 디스크에 저장하지 않고 메모리에 저장하는 최소 크기
location: /users/charming/temp # 업로드된 파일이 임시로 저장되는 디스크 위치
max-file-size: 10MB # 한개 파일의 최대 사이즈
max-request-size: 10MB # 한개 요청의 최대 사이즈

특이한 점은 클라이언트가 파일 업로드를 하면, Tomcat이 디스크에 임시 파일을 생성한다는 점입니다. file-size-threshold에 설정한 용량을 넘어가게 되면 디스크에 임시 파일을 생성합니다. 디스크에 생성하지 않는 경우에는 메모리에 올려 사용하게 되므로 적절한 용량 설정이 필요합니다.

생성된 임시 파일은 요청 종료 시점에 MultipartResolver.cleanupMultipart()가 호출되며 삭제됩니다.
하지만, 업로드 중 장애가 발생하는 등 삭제되지 않고 남아있는 경우가 종종 발생합니다. 이 경우에는 파일이 저장되는 위치를 잘 파악하고, 관리해 줄 필요가 있습니다.

public String uploadMultipartFile(MultipartFile file, String dirName) throws IOException {
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentLength(file.getSize());
metadata.setContentType(file.getContentType());
String filePath = dirName + "/" + S3FileUtil.createSaveFileNameFromFileName(file.getOriginalFilename());
amazonS3.putObject(new PutObjectRequest(bucket, filePath, file.getInputStream(), metadata));
return S3FileUtil.getFullPath(bucket, filePath);
}주소를 반환하는 MultipartFile 업로드 코드입니다. 위 코드는 한 번의 요청에 하나의 파일을 업로드하는 경우이며, 한 번에 여러 파일을 업로드할 수도 있습니다.
테스트
file-size-threshold 값을 1000MB로 설정한 후, 약 720MB짜리 파일을 Multipart 방식으로 업로드 했습니다.

위와 같이 Heap 메모리가 사용되고,
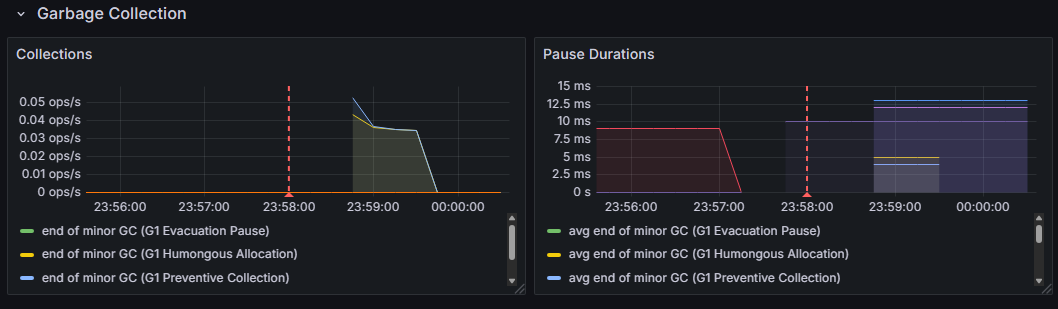
해당 메모리에 대한 가비지 컬렉션이 실행됩니다.
반면, file-size-threshold 값보다 큰 파일을 업로드 하는 경우에는 JVM Heap을 사용하지 않습니다.

왜 임시 저장을 하는가?
설정 값에 따라 디스크에 임시 저장 혹은 메모리에 캐시하는 이유가 궁금했습니다.
보안, 네트워크 에러 등 여러 이유가 있지만, 우리에게 와닿는 것들을 추려볼 수 있습니다.
1. 요청으로 들어오는 여러 종류의 데이터 분리
2. MultipartFile 인터페이스의 다양한 기능 사용
3. 리사이징, 썸네일 추출 등 전처리
특히, 2번이나 3번같은 추가 작업이 필요한 경우 어딘가에 파일을 저장해야 하므로 임시 파일을 생성합니다.
Multipart 방식은 Multipart라는 이름처럼 요청 본문이 여러 파트로 구성되어 있습니다. 각 파트는 File, JSON과 같은 데이터 등 여러 종류로 구성됩니다.
POST /upload HTTP/1.1
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary
------WebKitFormBoundary
Content-Disposition: form-data; name="metadata"
Content-Type: application/json
{
"userId": "1",
"nickname": "hello"
}
------WebKitFormBoundary
Content-Disposition: form-data; name="file"; filename="image.jpg"
Content-Type: image/jpeg
(Binary File Data)
------WebKitFormBoundary--위와 같이 Boundary로 나눠져 있으며, '--'으로 마지막 Boundary임을 표현합니다.
각 바운더리를 구분하고, 파일은 온전한 파일로 따로 저장한 후 MultipartFile에서 제공하는 다양한 기능을 사용할 수 있도록 합니다. 파일이 어딘가에 저장되어 있으므로 전처리 과정 또한 거칠 수 있게 됩니다.
이처럼 Multipart 방식은 여러 데이터를 한 번에 보낼 수 있으며, 파일에 대한 다양한 기능을 사용할 수 있다는 장점이 있지만, 임시 저장 과정을 거치게 되므로 속도와 저장 공간을 생각했을 때 불리하다는 단점이 있습니다. 특히, 파일이 대용량일수록 임시 저장하는 파일의 용량이 커지므로 임시 파일로 저장하는 시간과 차지하는 공간이 많이 소모되므로, 다른 방식을 생각해 볼 필요가 있습니다.
2) Octet-Stream

다음으로, Octet-Stream 업로드 방식은 HttpServletRequest의 InputStream을 사용합니다. 파일을 보낼 때, application/octet-stream 타입으로 보내며, 다른 데이터와 함께 전송할 수 없습니다.
Multipart 방식과는 다르게 파일을 디스크나 메모리에 저장하지 않기 때문에 이미지 리사이징과 같은 전처리 작업은 불가능합니다.
public String uploadStreamFile(HttpServletRequest request, String dirName) throws IOException {
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentLength(request.getContentLengthLong());
metadata.setContentType(request.getContentType());
String filePath = dirName + "/" + S3FileUtil.createSaveFileNameFromContentType(request.getContentType());
amazonS3.putObject(new PutObjectRequest(bucket, filePath, request.getInputStream(), metadata));
return S3FileUtil.getFullPath(bucket, filePath);
}
Octet-Stream 방식은 디스크 혹은 메모리 공간에서 효율적입니다. 하지만, 파일 외의 다른 데이터를 보내려면 분할 요청 등 별도 방법이 필요합니다. 또, 바이너리에서 파일 데이터를 구분할 수 없기 때문에 한 번의 요청에 하나의 파일만을 업로드 할 수 있다는 특징이 있습니다.
그리고, 네트워크 상황에 영향을 많이 받습니다. 전송 시 상황에 따라 편차가 크며, 대용량 파일 업로드 중 오류 발생 시 처음부터 다시 전송해야 되므로 시간이 오래 걸릴 수 있습니다.
테스트
위 멀티 파트 방식 테스트 이후 바로 동일한 설정 값과 파일로 Octet-Stream 방식도 테스트를 해보았습니다.

추가로 사용되는 메모리가 없었습니다.

마찬가지로 가비지 컬렉션도 실행되지 않았습니다.
Client - S3 직접 업로드
3) Pre-Signed Url
업로드 시 서버를 경유하지 않고 클라이언트가 직접 S3에 파일을 업로드하는 방식은 Pre-Signed Url을 사용하여 구현할 수 있습니다.
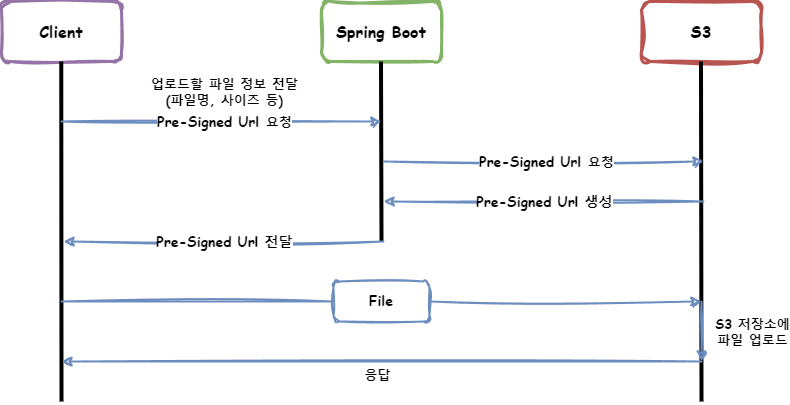
그래도 서버에 요청을 한 번 보내긴 하는데, Pre-Signed Url을 요청하면, 서버는 이를 만들어서 응답합니다. 클라이언트는 해당 응답에 포함된 Url로 파일을 보내면 S3에 업로드가 됩니다.
public String generatePreSignedUrl(String contentType, String dirName) {
Date expiration = Date.from(LocalDateTime.now().plusMinutes(10).atZone(ZoneId.systemDefault()).toInstant());
String filePath = dirName + "/" + S3FileUtil.createSaveFileNameFromContentType(contentType);
GeneratePresignedUrlRequest generatePresignedUrlRequest = new GeneratePresignedUrlRequest(bucket, filePath)
.withMethod(HttpMethod.PUT)
.withExpiration(expiration);
return amazonS3.generatePresignedUrl(generatePresignedUrlRequest).toString();
}만료 시간을 정해주고, Url을 만들어줍니다.
{
"success": true,
"data": {
"fileUrl": "https://exam-bucket.s3.ap-northeast-2.amazonaws.com/post/869c6b73-4023-4e06-b3ee-2cb266e8484a.mp4?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20250307T121443Z&X-Amz-SignedHeaders=host&X-Amz-Expires=599&X-Amz-Credential=AKIA6GBMDIT2HE3Z7NVW%2F20250307%2Fap-northeast-2%2Fs3%2Faws4_request&X-Amz-Signature=eb616891763eeb0d67dda4dc3361bf4bec68d3d8211147b4391d21264495cf3e"
}
}위와 같은 url이 만들어지고, 해당 url로 업로드 요청을 보냅니다.
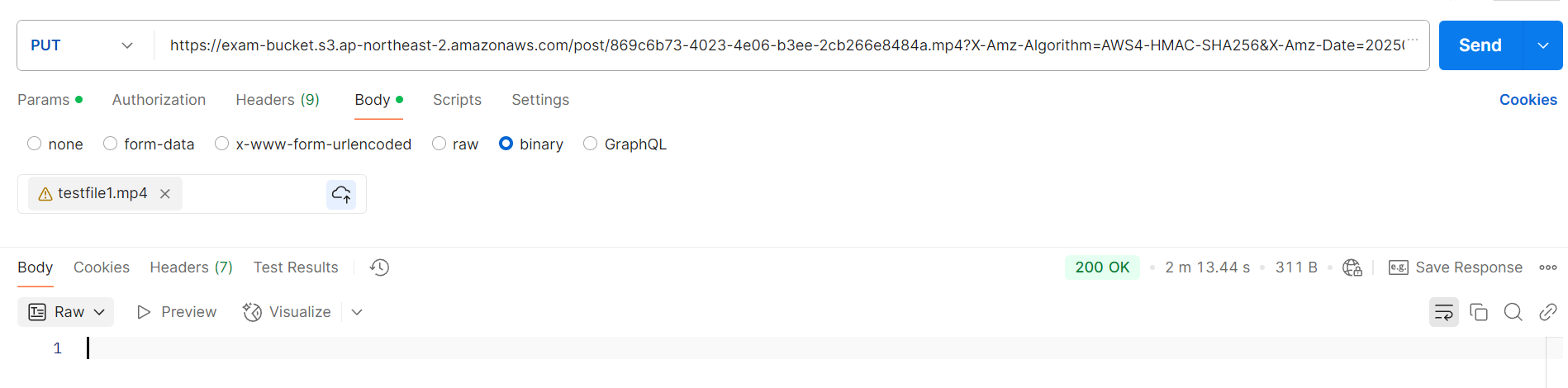
업로드에 성공하면 200 OK 응답을 받고,
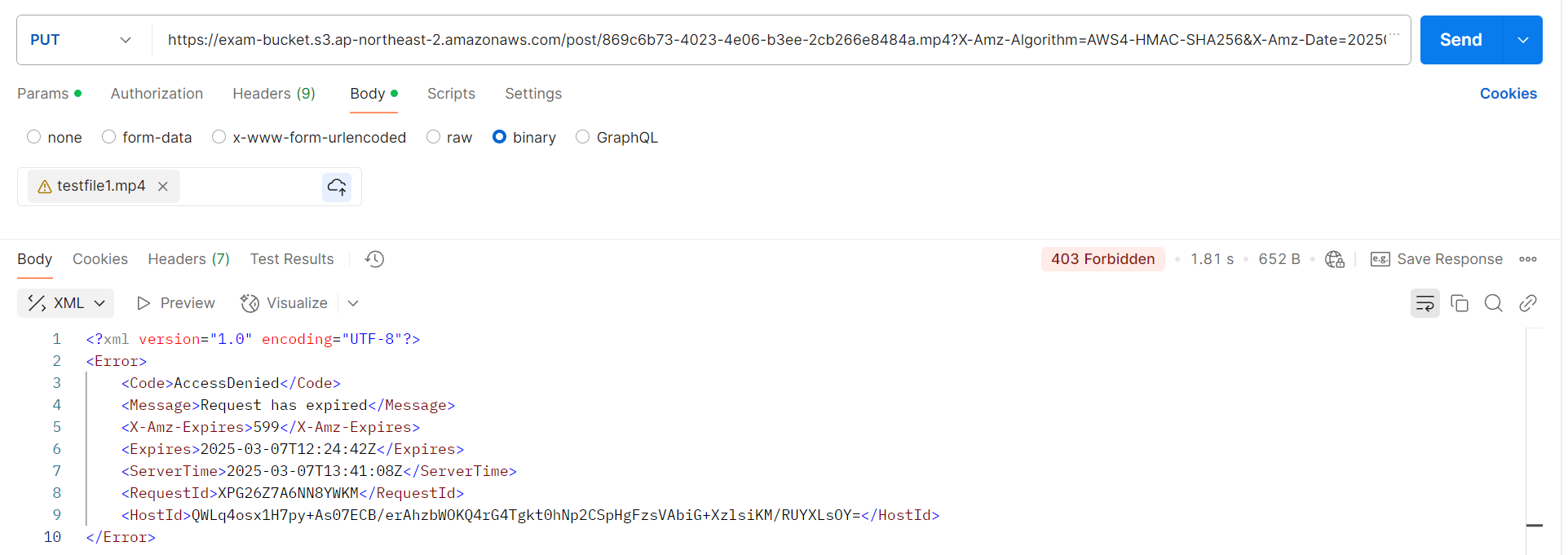
만료되거나 잘못된 경로로의 요청의 경우 403에러를 응답받습니다.
2. 대용량 파일 업로드
대용량 파일의 경우 업로드 시간이 오래 걸릴 수 있습니다. 1.5GB 정도의 파일을 업로드 하는 데 2분 이상이 걸렸고, 만약 더 큰 파일을 업로드 해야 하는 요구사항이 있다면 이를 개선할 필요가 있습니다.
바탕이 되는 이론은 큰 파일을 작은 파일로 쪼개서 업로드 하는 것입니다.
위에서 살펴본 방식을 바탕으로 진행할 수 있는데, 청크 단위로 쪼갠 방식과 AWS Multipart 방식으로 나누어 볼 수 있습니다. 두 방식 모두 큰 파일을 더 작은 크기로 쪼개서 업로드를 하는 방법입니다. 직접 구현하는 방식은 tus 프로토콜을 사용하는 등의 방식으로 많은 기능을 구현할 수 있으며, 제가 채택한 AWS Multipart에 대해 자세히 알아보도록 하겠습니다.
AWS Multipart
AWS Multipart는 하나의 큰 파일을 여러 파트로 나누어 사용합니다. 큰 파일을 작은 파일 여러 개로 쪼개고, 클라이언트는 각 청크를 업로드합니다. 모든 파트가 업로드 완료되면, AWS S3에서 청크를 재조립하여 하나의 파일로 만듭니다.
업로드 중 취소, 재개가 가능하다는 특징이 있습니다.
Rest API (서버 경유)
서버에 각 파트를 전송하고, 서버는 S3에 전송한 후, 모든 파트를 조합하여 최종 파일을 완성합니다.
AWS 문서에서 소개하는 AWS 멀티파트 업로드에 대해 살펴보겠습니다.

업로드 프로세스
1. 멀티파트 업로드 시작
2. 객체(파일) 파트 업로드
3. 멀티파트 업로드 완료
위 세 단계를 거칩니다.
마지막 단계인 멀티파트 업로드 완료 요청이 전송되면 S3는 업로드된 각 파트를 모아 완전한 객체(파일)을 구성하고, 다른 객체들과 같이 해당 객체에 액세스 할 수 있습니다.
1. 멀티파트 업로드 시작
- 멀티파트 업로드 시작 요청을 보낼 때는 체크섬 유형을 지정해야 합니다.
- S3 멀티파트 업로드의 고유 식별자인 업로드 ID가 포함된 응답을 반환받습니다.
- 파트를 업로드하거나 중지하는 등 작업을 수행하고자 할 때, 이 업로드 ID가 필요합니다.
- 업로드되는 객체를 설명하는 메타데이터를 제공하려는 경우 멀티파트 업로드 시작 요청에서 제공해야 합니다.
public InitiateMultipartUploadResult initMultipartUpload(String fileType, String dirName) {
ObjectMetadata metadata = new ObjectMetadata();
String contentType = S3FileUtil.extractExtFromContentType(fileType);
metadata.setContentType(contentType);
String filePath = dirName + "/" + S3FileUtil.createSaveFileNameFromContentType(contentType);
return amazonS3.initiateMultipartUpload(new InitiateMultipartUploadRequest(bucket, filePath, metadata));
}파일의 타입을 요청으로 받아 메타데이터로 저장했습니다.
위 함수의 리턴값에서 uploadId를 추출하여 클라이언트에게 반환됩니다.
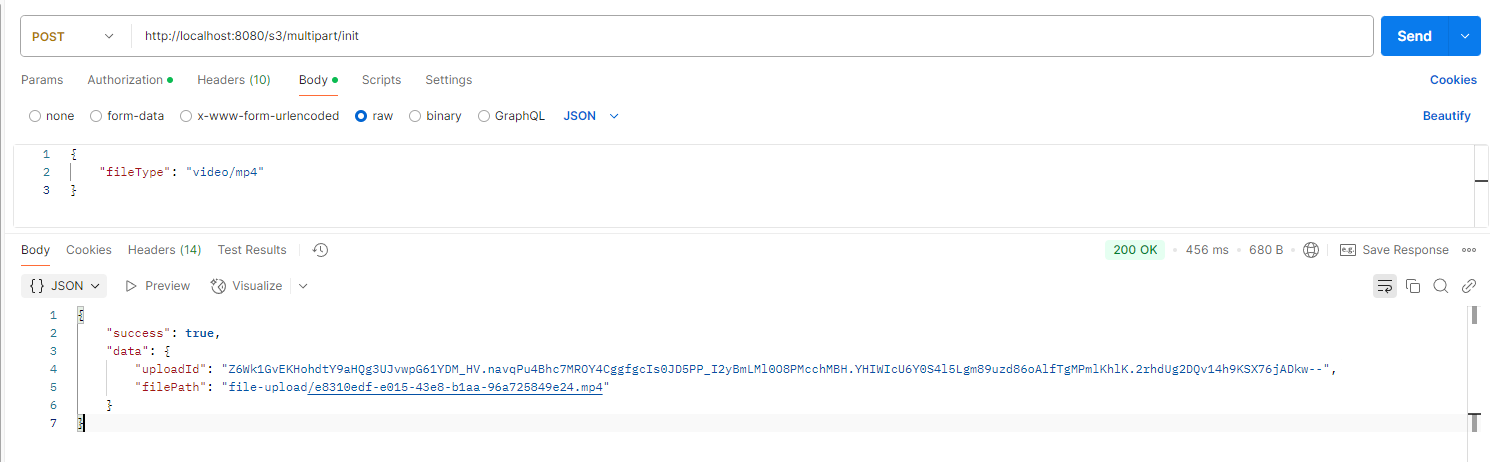
2. 객체 파트 업로드
- 파트를 업로드할 때 업로드 ID와 함께 파트 번호(1~10,000)를 지정해야 합니다.
- 파트 번호를 연속적으로 지정할 필요는 없습니다.
- 이전에 업로드한 파트와 동일한 파트 번호로 업로드하면 덮어쓰게 됩니다.
- 파트 업로드 시 ETag 값을 응답받습니다.
- 해당 ETag 값은 멀티파트 업로드를 완료하기 위해 필요합니다. (업로드가 완료되고, 모든 파트가 통합되면 모든 파트는 하나의 ETag에 속하게 됩니다)
public UploadPartResult uploadStreamChunk(String uploadId, int partNumber, String filePath, HttpServletRequest request) throws IOException {
UploadPartRequest uploadPartRequest = new UploadPartRequest();
uploadPartRequest.setBucketName(bucket);
uploadPartRequest.setUploadId(uploadId);
uploadPartRequest.setPartNumber(partNumber);
uploadPartRequest.setKey(filePath);
uploadPartRequest.setPartSize(request.getContentLengthLong());
uploadPartRequest.setInputStream(request.getInputStream());
return amazonS3.uploadPart(uploadPartRequest);
}위에서 살펴본 것처럼 청크 단위로 파트를 업로드 할 때에도 MultipartFile로 받는 방법과, Octet-Stream으로 받는 방법이 있습니다. MultipartFile은 파일을 저장하기 때문에 대용량 업로드에서 큰 단점이 있을 것이며, 저는 Stream을 사용해서 청크 단위로 업로드 코드를 작성했습니다.
3. 멀티파트 업로드 완료
- 멀티파트 업로드를 완료하면 S3는 파트 번호를 바탕으로 오름차순으로 각 부분을 결합하여 객체를 완성함. 위에서 파트 번호를 연속적으로 지정할 필요는 없다고 했는데, 번호의 크기는 중요합니다.
- 멀티파트 업로드 시작 시 메타데이터를 함께 제공한 경우, S3는 객체에 해당 메타데이터를 연결함.
- 완료 요청이 성공적으로 수행되면 각 파트는 더 이상 존재하지 않게 됩니다.
- 멀티파트 업로드 완료 요청에는 업로드 ID, 각 파트 번호 및 ETag값 List가 필요합니다.
- 응답으로 각 파트를 합친 하나의 ETag 값이 반환됩니다.
public CompleteMultipartUploadResult completeMultipartUpload(String uploadId, List<CompleteS3MultipartUploadRequest.Part> partList, String filePath, String dirName) {
List<PartETag> partETags = partList.stream()
.map(part -> new PartETag(part.getPartNumber(), part.getETag()))
.collect(Collectors.toList());
CompleteMultipartUploadRequest completeMultipartUploadRequest =
new CompleteMultipartUploadRequest(bucket, filePath, uploadId, partETags);
return amazonS3.completeMultipartUpload(completeMultipartUploadRequest);
}
Pre-Signed Url (클라이언트 직접 업로드)
AWS Multipart 업로드 방식도 클라이언트가 직접 S3에 업로드(pre-signed url)하도록 할 수 있습니다.
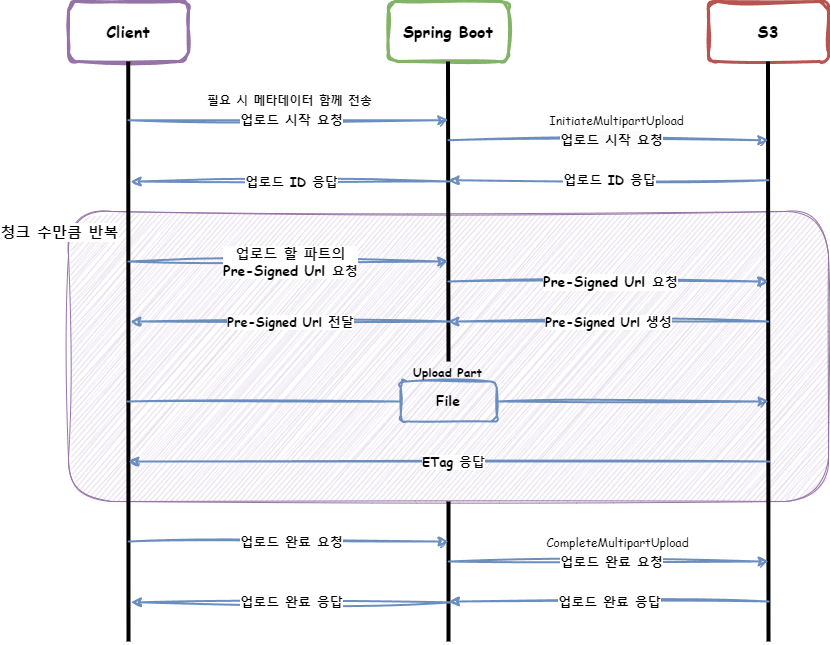
1. 멀티파트 업로드 시작
2. 각 파트별 pre-signed url 생성
3. 객체(파일) 파트 업로드
4. 멀티파트 업로드 완료
Rest API 방식처럼 멀티파트 업로드 시작과 완료 요청 사이에 작업이 진행됩니다. 각 파트별로 pre-signed url를 발급받고, 클라이언트가 직접 S3로 객체 파트를 업로드합니다.
파트별 Pre-Signed Url 생성
public String generatePreSignedUrlForMultipartUpload(String uploadId, int partNumber, String filePath, String dirName) {
Date expiration = Date.from(LocalDateTime.now().plusMinutes(10).atZone(ZoneId.systemDefault()).toInstant());
GeneratePresignedUrlRequest generatePresignedUrlRequest = new GeneratePresignedUrlRequest(bucket, filePath)
.withMethod(HttpMethod.PUT)
.withExpiration(expiration);
generatePresignedUrlRequest.addRequestParameter("uploadId", uploadId);
generatePresignedUrlRequest.addRequestParameter("partNumber", Integer.toString(partNumber));
return amazonS3.generatePresignedUrl(generatePresignedUrlRequest).toString();
}
업로드 id와 파트 번호를 addRequestParameter()에 넣어준 후, pre-signed url을 생성합니다.
멀티파트 업로드 시작과 완료 요청은 Rest API 방식과 동일하고, 파트 업로드는 발급받은 Pre-Signed Url로 클라이언트가 직접 업로드합니다. 마찬가지로 모든 파트가 업로드 된 후, 완료 요청을 보내면 S3에서 조합하여 완성된 파일을 만들어냅니다.
추가 기능
AWS Multipart는 취소, 재개, 추적 등 업로드를 진행하며 발생할 수 있는 여러 문제를 위한 기능을 제공합니다.
업로드 취소
업로드를 취소해야 할 때, 이미 업로드된 파트들을 S3에서 제거할 수 있습니다. 업로드가 이미 완료된 상태(업로드 완료 요청 성공)이면, 업로드 취소가 적용되지 않습니다. 또한, 업로드 취소가 성공하면 uploadId는 더 이상 유효하지 않게 됩니다.
public void abortMultipartUpload(String uploadId, String filePath) {
AbortMultipartUploadRequest abortMultipartUploadRequest =
new AbortMultipartUploadRequest(bucket, filePath, uploadId);
amazonS3.abortMultipartUpload(abortMultipartUploadRequest);
}불완전한 멀티파트들은 스토리지 공간을 차지하기 때문에, 비용이 부과될 수 있습니다. AWS CLI로 직접 삭제하거나 S3 LifeCycle 설정을 통해 자동으로 삭제되도록 할 수 있습니다.

업로드 추적
파일 업로드 시 %로 업로드 현황을 보여줘야 하는 경우가 있습니다. 이 경우, 각 파트를 추적하여 현재 업로드가 어느정도 진행됐는지 파악할 수 있습니다.
- 파일 업로드 도중, 현재 몇 바이트(%)가 전송되었는지 모니터링합니다.
- SDK (TransferManager) 의 ProgressListener를 사용하여 구현 가능합니다.
서버에 각 파트를 저장하고, S3에 업로드하는 경우 서버를 거쳐 확인할 수 있으나, 대용량 파일 전송 시 서버에 저장하는 것 자체가 부담이 될 수 있습니다.
업로드 재개
업로드 도중 네트워크 오류/앱 종료 등으로 중단된 경우, 이미 업로드된 파트를 재활용해서 다시 시작할 수 있습니다.
Pre-Signed Url 방식으로 AWS S3 Multipart 진행하고 있기 때문에, 업로드가 중단된 경우 클라이언트는 서버에게 현재까지 업로드 된 파트 번호와 ETag를 받고, 그 이후 파트부터 다시 업로드합니다.

클라이언트는 업로드된 파트 번호 이후부터 다시 업로드 할 수 있습니다.
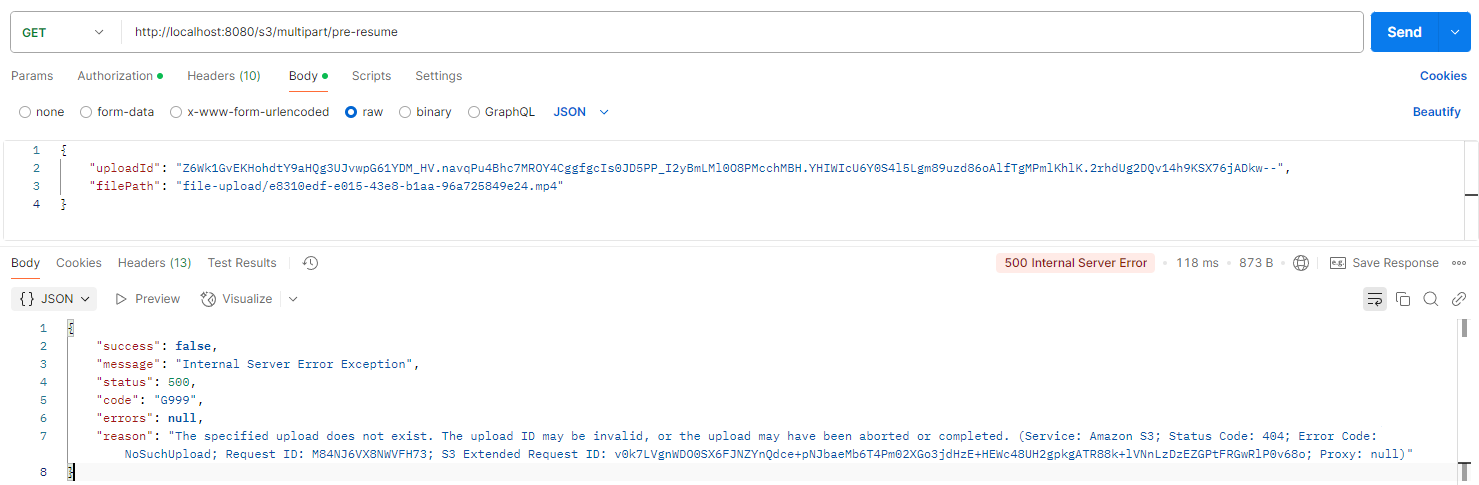
완료 혹은 취소 후에는 사용할 수 없는 uploadId라는 에러가 발생합니다.
단순히 파일 업로드를 구현하는 것에도 여러 방법이 있다는 것을 알 수 있습니다. 사실 여러 프로젝트에서 아무 생각 없이 Multipart 방식으로 구현을 해왔었는데, 상황에 맞는 방식이 존재함을 알게 되었습니다. 내부에서 일어나는 일을 알고 사용한다면 목적을 달성하는 데 더욱 도움이 될 것 같습니다!
특히, 주로 사용되는 방법인 Multipart 방식을 스프링에서 사용하게 되면 디스크에 저장한다는 점과 대용량 파일을 업로드 할 때는 자원을 잘 생각해야 됩니다.
'Project' 카테고리의 다른 글
| Bulk 연산으로 Write 작업 개선하기 (0) | 2025.03.13 |
|---|---|
| 외부 API 호출 시 고려할 것 (0) | 2025.03.10 |
| 배치 프로세스 리팩토링 (0) | 2025.03.03 |
| Swagger 코드 분리, Http Status (0) | 2025.02.28 |
| 파일 업로드 로직 변경 (0) | 2024.11.20 |