

0. 개요
프로젝트를 진행하며 사용자가 보게 될 '플레이리스트' 구성에 있어 '시리즈'와 '시리즈가 아닌 콘텐츠' 구분 로직이 복잡했습니다. 특히, OTT 서비스의 홈 화면 API들은 자주 호출되기 때문에 사용자와 데이터가 많다면 병목이 있을 것이라고 예상했습니다.
따라서 K6 테스트 후 병목 지점을 수치로 확인하고, 원인 파악 및 개선 작업을 진행하기로 했습니다.



대표적으로
- 인기 차트 플레이리스트 조회
- Top Tag(태그 기반) 플레이리스트 조회
- 시청 이력 플레이리스트 조회
위 세 가지 API가 홈 화면에서 호출됩니다.
겹치는 로직이 많아 인기 차트 플레이리스트 조회 중심으로 개선 과정을 정리했습니다.
테스트 환경
다른 요소들은 제외하고, 요청-응답 중심으로 간단하게 그림으로 나타내면 아래와 같습니다.

서버 스펙
| 자원 | 타입 | vCPU | 메모리 | 디스크/스토리지 |
| user-api EC2 | t3.micro | 2 | 1 GiB | gp3 8GB |
| redis EC2 | t3.micro | 2 | 1 GiB | gp3 8GB |
| RDS MySQL | db.t3.micro | 2 | 1 GiB | gp3 20GB |
더미 데이터
스크립트를 작성하여 규모별로 데이터셋을 생성했습니다. Small/Mideum/Large/XLarge 4개로 구분했으며, 다양한 데이터 규모에서 문제 지점을 파악하기 위해 나눴습니다.

테스트 도구
- 부하 테스트를 위해 K6를 사용했습니다. 스크립트를 작성해서 VU 규모별로 테스트를 진행했습니다.
- 기본적으로 Prometheus, Grafana를 사용하여 메트릭을 수집하고, 대시보드에서 확인했습니다.
- 주로 CPU, Heap, HTTP/DB Connection 등 서버 자원을 확인하는 용도로 사용했습니다.
개선 전 테스트 결과

XLarge 데이터 셋에서 K6 부하 테스트를 진행해보니 데이터가 많은 상태에서 긴 쿼리 + 많은 쿼리 + 많은 요청으로 인해 타임아웃이 발생하는 경우가 매우 많아 결과를 확인하기 어려웠습니다. 그래서 우선 Large로 부하 테스트 결과를 보고, 단 건 확인은 XLarge로 진행하기로 결정했습니다.
홈 화면의 API는 Large 데이터 셋에 데이터가 그리 많지 않음에도 응답 시간이 꽤 걸렸습니다. VU100 선에서 벌써 평균 응답 시간이 1.5초 이상 나타났습니다.
더 적은 데이터 셋에서는 모든 API의 Avg가 거의 비슷하게 나타났습니다. 비효율적인 쿼리가 있더라도 데이터 수가 적기 때문에 빠르게 실행되어 대부분 네트워크 왕복 시간만 필요했기 때문입니다.
1. 로직 파악
API 호출 결과, 생각보다 많은 쿼리가 발생했고, 소수의 긴 쿼리가 존재했습니다. 흐름을 파악하고 쿼리 수를 줄이기 위해 API의 로직을 먼저 정리했습니다.

하나의 흐름으로 보면 위 그림과 같고, 붉은 색으로 표시된 부분에서 가장 긴 두 쿼리와 N+1 문제가 발생합니다.
첫 번째 쿼리
- ACTIVE/PUBLIC/COMPLETED 상태 필터링
- 시리즈/단편 콘텐츠 필터링
- 미디어 북마크 순 정렬
- 상위 20개 반환
두 번째 쿼리
- 페이지네이션 시 Page 인터페이스 사용으로 인한 count() 쿼리 발생
N+1 문제
- 가져온 콘텐츠가 시리즈일 경우 이어보기 지점 표시를 위해 해당 시리즈의 모든 콘텐츠 중 가장 최근 시청 미디어를 찾아야 함
- 첫 번째 쿼리에서 가져온 미디어 수만큼 반복

이어보기 지점이라 함은 이렇게 포스터 아래에 표시되는 시청 기록을 말합니다.
2. 쿼리 및 로직 개선
인기 차트 플레이리스트 API를 포스트맨으로 호출해 로그를 확인했습니다. 응답 시간은 약 11초 정도 걸렸습니다.
2개의 주요 쿼리와 N+1 쿼리로 인해 상당한 지연이 발생했습니다.
2-1. 1번 쿼리: 3096ms
INFO 528 --- [io-8080-exec-10] p6spy : [STATEMENT] | 3096 ms |
select
m1_0.id,
m1_0.bookmark_count,
...
from media m1_0
where
m1_0.status='ACTIVE' and m1_0.public_status='PUBLIC' and m1_0.media_status='COMPLETED'
and (
m1_0.media_type='SERIES'
or m1_0.media_type='CONTENTS'
and not exists(select 1 from contents c1_0 where c1_0.media_id=m1_0.id and c1_0.series_id is not null)
)
order by m1_0.bookmark_count desc
limit 0, 20
쿼리 한 번에 3096ms가 걸렸고, 이를 분석하고자 Explain (+ Analyze)를 통해 실행 계획을 확인해봤습니다.


크게 두 가지 문제로 인해 쿼리 실행 시간이 길어짐을 확인할 수 있었습니다.
문제 1. 수많은 서브쿼리 Loop
콘텐츠가 시리즈의 에피소드인 경우와 시리즈가 아닌 단편 영화와 같은 일반 콘텐츠인 경우를 확실하게 구분지어야 하는데,
시리즈에 소속된 에피소드를 제거하기 위한 조건으로 Where절 안에 OR + 서브쿼리가 필요했습니다.
플레이리스트에 구성되는 콘텐츠는 '더글로리 1화'와 같은 단독 에피소드가 아닌, 시리즈 단위 혹은 단편 영화와 같은 콘텐츠가 되어야 하기 때문입니다.

Explain Analyze 결과를 보면, NOT EXISTS 서브쿼리의 loop 횟수가 240,070회에 달합니다.
-> Select #2 (subquery in condition; dependent)
-> Single-row index lookup on c1_0 using uk_contents_media (media_id=m1_0.id)
(actual time=0.00846..0.00846 rows=1 loops=240070)서브쿼리 1회 실행은 유니크 인덱스 lookup이라 약 0.00846ms로 빠르지만, 이것이 24만 번 반복되면 약 2초가 소모됩니다. 전체 쿼리 시간 중 풀스캔이 865ms, 나머지 약 2초가 이 서브쿼리 반복에서 발생한 것입니다.
상관 서브쿼리와 Anti-Join
현재 NOT EXISTS 내부의 서브쿼리는 외부 테이블(Media)의 현재 행을 참조하는 상관 서브쿼리로, Media의 행마다 Contents를 반복하며 조회합니다. 이는 외부 행이 바뀔 때마다 매번 다시 실행되어야 합니다.
하지만, MySQL 옵티마이저는 NOT EXISTS 상관 서브쿼리를 Anti-Join으로 변환하는 최적화를 지원하기 때문에 상관 서브쿼리 자체가 문제는 아닙니다.
Anti-Join은 두 테이블을 한 번 조인하여 매칭되지 않는 행만 남기는 연산입니다. 행마다 서브쿼리를 반복하는 것이 아니라 media 전체와 contents 전체를 한 번에 매칭하는 하나의 조인 동작으로 바뀌는 것입니다.
이 최적화가 적용되었다면 24만 건의 loop는 발생하지 않았을 것입니다.
OR 조건
문제는 NOT EXISTS가 OR 조건 안에 감싸져 있기 때문에 발생했습니다.
MySQL의 세미조인/안티조인 최적화는 서브쿼리가 WHERE 최상위 레벨에 AND로 연결되어 있을 때 적용됩니다. OR 안에 들어가는 순간 옵티마이저가 Anti-Join 변환을 수행하기 어려워져 의도한 대로 동작하지 않을 수 있습니다.
Anti-Join은 이 테이블 전체와 저 테이블 전체를 한 번에 매칭하는 연산입니다. 그런데 OR 조건이 있으면
media_type = 'SERIES'인 행 → contents 조인 자체가 필요 없음
media_type = 'CONTENTS'인 행 → contents 조인이 필요함행마다 조인을 해야 할지 말아야 할지가 달라집니다. 조인을 할지 말지 행 단위로 분기하는 것은 조인 연산의 구조와 맞지 않기 때문에, 옵티마이저는 Anti-Join 변환을 포기하고 원래 의미 그대로 행 하나씩 서브쿼리를 평가하는 Dependent Subquery로 실행하게 됩니다.
정리
| 요소 | 단독으로 문제인가 | 이유 |
| 상관 서브쿼리 | X | Anti-Join 최적화 가능 |
| NOT EXISTS | X | Anti-Join 최적화 가능 |
| OR + NOT EXISTS | O | Anti-Join 최적화 차단 → 행마다 서브쿼리 반복 |
결국 상관 서브쿼리 자체가 아니라, OR 조건이 Anti-Join 최적화를 차단하여 상관 서브쿼리가 행마다 반복 실행되는 것이 문제입니다. 실행 계획에서는 50만 행 중 media_type='CONTENTS'인 약 24만 행 각각에 대해 서브쿼리가 1번씩 실행되어, loops=240,070이라는 수치가 나타난 것입니다.
해결 방안 1. 반정규화 ✅
Media 테이블에 단독 콘텐츠임을 나타내는 is_standalone 컬럼을 추가하여 혼자 노출될 수 있는지(Series/단편 Contents) 표시하는 방법입니다. 이를 통해 Media 테이블만 보고도 플레이리스트 포함 여부를 찾아갈 수 있게 됩니다.
WHERE m1_0.status = 'ACTIVE'
AND m1_0.public_status = 'PUBLIC'
AND m1_0.media_status = 'COMPLETED'
AND m1_0.is_standalone = true
장점: NOT EXISTS 완전 제거 / 인덱스 포함 가능
단점: 콘텐츠 수정 시 동기화 필요
팀에서는 해당 방식인 반정규화를 선택했습니다. 그 이유로 아래 세 가지가 대표적입니다.
- OR과 NOT EXISTS 근본적 제거
- 필요 시 인덱스 포함 가능
- 백오피스에서 가능한 미디어 수정은 자주 일어나지 않음
OR과 NOT EXISTS가 모두 사라지므로, 서브쿼리 루프 240,070회가 0회가 됩니다. 또한, WHERE 필터링만 남기 때문에 복합 인덱스를 구성하면 풀스캔과 filesort까지 함께 해결할 수 있습니다.
단점은 반정규화로 인한 동기화입니다. 콘텐츠가 시리즈에 편입되거나 시리즈에서 빠질 때 is_standalone 값을 함께 갱신해야 합니다. 이 동기화가 누락되면 플레이리스트에 에피소드가 노출되거나, 반대로 단편 콘텐츠가 누락되는 정합성 문제가 발생합니다.
다만, 이 프로젝트에서는 미디어 수정이 백오피스에서만 이루어지고, 그 빈도가 낮기 때문에 동기화 비용 대비 조회 성능 이득이 더 크다고 판단하여 이 방식을 선택했습니다.
Media_Type에 EPISODE를 추가하여 Contents의 타입을 에피소드/단편으로 세분화하는 것(해결 2)이 더 근본적인 해결 방법이라고 생각했습니다. 하지만, 현재 다른 API 로직에서 매우 많이 사용 중이므로 변경 범위가 상당히 컸기 때문에 컬럼을 기존 로직 수정을 최소화 할 수 있도록 컬럼을 추가하는 방식으로 결정했습니다.
해결 방안 2. Media_Type에 EPISODE 추가
Media_Type을 세분화하여 Contents를 EPISODE/CONTENTS로 분리하는 방식입니다. 현재는 Media_Type이 SERIES/CONTETNS/SHORT_FORM 이렇게 세 가지가 존재하며, CONTENTS 타입에 에피소드와 단일 콘텐츠가 모두 존재합니다.
WHERE m1_0.status = 'ACTIVE'
AND m1_0.public_status = 'PUBLIC'
AND m1_0.media_status = 'COMPLETED'
AND m1_0.media_type IN ('SERIES', 'CONTENTS')
장점: 도메인 의미 명확 / NOT EXISTS 완전 제거
단점: 기존 Contents 참조하는 코드 모두 수정 / 영향 범위 큼
반정규화와 마찬가지로 OR과 NOT EXISTS가 완전히 사라집니다. 에피소드인지 아닌지가 타입 자체에 표현되어 있는 가장 정석적인 해결 방법입니다.
하지만, Media_Type은 현재 프로젝트 전반에 걸쳐 매우 광범위하게 참조되고 있었습니다. media_type = 'CONTENTS'로 분기하는 모든 코드에서 EPISODE를 함께 고려해야 하고, QueryDSL 조건, Enum 클래스, 프론트엔드 분기 등 변경 범위가 상당히 컸기 때문에 이번 시점에서는 선택하지 않았습니다.
가장 정석적인 해결 방법이라고 생각하지만, 앞서 정리한 것처럼 변경 사항이 너무 많아지기 때문에 지금 시점에서는 변경 범위가 적은 방안을 선택하고자 해당 방식을 선택하지 않았습니다.
해결 방안 3. Union All 사용
Series 쿼리와 단독 Contents 쿼리를 분리하여 OR을 제거하고, UNION ALL로 합치는 방식입니다.
OR 조건을 UNION ALL로 분리하면 각 서브쿼리가 독립적인 WHERE 절에 AND로 연결되므로, Anti-Join 최적화가 적용될 가능성이 생깁니다.
장점: 스키마 변경 x
단점: OR는 분리하지만, NOT EXISTS 자체가 남음 / 쿼리 2개로 복잡함
-- 변경 후 쿼리
(
SELECT
m1_0.id, m1_0.bookmark_count, m1_0.created_date, ...
FROM media m1_0
WHERE m1_0.status = 'ACTIVE'
AND m1_0.public_status = 'PUBLIC'
AND m1_0.media_status = 'COMPLETED'
AND m1_0.media_type = 'SERIES'
)
UNION ALL
(
SELECT
m1_0.id, m1_0.bookmark_count, m1_0.created_date, ...
FROM media m1_0
WHERE m1_0.status = 'ACTIVE'
AND m1_0.public_status = 'PUBLIC'
AND m1_0.media_status = 'COMPLETED'
AND m1_0.media_type = 'CONTENTS'
AND NOT EXISTS (
SELECT 1 FROM contents c1_0
WHERE c1_0.media_id = m1_0.id
AND c1_0.series_id IS NOT NULL
)
)
ORDER BY bookmark_count DESC
LIMIT 0, 20;해당 방식은 스키마 변경이 없다는 큰 장점이 있지만, NOT EXISTS의 반복을 줄이지 못 한다는 한계가 있습니다. 현재 해결하고자 하는 문제는 OR 제거라기보단, OR를 비효율적으로 수행하는 서브쿼리 제거이므로 해당 방식은 선택하지 않았습니다.
OR이 사라지면서 두 번째 쿼리의 NOT EXISTS가 WHERE 최상위에 AND로 연결되므로, 옵티마이저가 Anti-Join으로 변환할 수 있는 구조가 됩니다. 스키마 변경 없이 쿼리만으로 개선할 수 있다는 점이 장점입니다.
하지만, Anti-Join 변환은 보장이 아닌 가능성입니다. 옵티마이저 버전, 테이블 통계 정보, 데이터 분포에 따라 여전히 Dependent Subquery로 실행될 수 있어서 EXPLAIN ANALYZE로 매번 확인이 필요합니다. 또한, NOT EXISTS 자체가 남아있으므로 쿼리 구조의 복잡성이 유지됩니다. 해결하고자 하는 핵심은 OR 제거가 아니라 서브쿼리 반복 실행의 제거이므로, 이를 구조적으로 보장하지 못하는 이 방식은 선택하지 않았습니다.
이와 비슷하게 Left Join으로 풀어내는 방식도 존재하지만, OR가 남아 있게 되어 옵티마이저가 효율적으로 처리하지 못 할 가능성이 존재합니다.
결국, or 조건을 없애고, 시리즈/콘텐츠 여부를 확정할 수 있도록 해 주어야 하는 문제였습니다.
적용
변경은 간단했습니다. 우선 컬럼 추가를 위해 Flyway를 작성하고, Media 엔티티에 컬럼을 추가했습니다.
저희는 QueryDSL로 쿼리를 작성하고 있었고, 이를 함수로 분리하여 표현하고 있었기 때문에 기존 로직(주석 부분)에서 새로 추가한 컬럼 확인 로직으로 변경해주면 바로 적용할 수 있었습니다.
private BooleanExpression isDisplayable() {
// return media.mediaType.eq(MediaType.SERIES)
// .or(media.mediaType.eq(MediaType.CONTENTS)
// .and(JPAExpressions.selectOne()
// .from(contents)
// .where(contents.media.id.eq(media.id)
// .and(contents.series.isNotNull()))
// .notExists()));
return media.isStandalone.isTrue();
}
반정규화 후 API 호출을 해 보니 3096ms -> 1323ms로 감소한 것을 확인할 수 있었습니다.
INFO 34772 --- [nio-8080-exec-6] p6spy: [STATEMENT] | 1323 ms |
select
m1_0.id,
m1_0.bookmark_count,
...
from
media m1_0
where
m1_0.status='ACTIVE'
and m1_0.public_status='PUBLIC'
and m1_0.media_status='COMPLETED'
and m1_0.is_standalone=true
order by
m1_0.bookmark_count desc
limit
0, 20
문제 2. 테이블 풀 스캔 + Filesort
반정규화를 통해 OR과 서브쿼리를 없앴지만, 여전히 비효율적인 쿼리가 실행되었습니다.


WHERE 절의 조건들과 ORDER BY 컬럼에 인덱스가 없어 풀스캔을 진행합니다. 데이터를 추린 후에도 북마크 수 기반 정렬이 필요하기 때문에, 풀스캔 + filesort가 발생합니다.
- 모든 데이터에 접근하여 필터링해야 함
- 남은 데이터에 대해 정렬까지 진행해야 함
Where 조건 필터링을 위한 도움과 효율적인 정렬을 위한 도움이 필요했고, 인덱스를 통해 해결 가능했습니다.
선택: 인덱스 추가 ✅
idx_media_trending (Status, Public_Status, Media_Status, is_standalone, bookmark_count DESC) 인덱스를 추가하는 방법입니다.
bookmark_count는 보통 '인기 차트'같이 역순(높은 순)정렬로 쓰입니다. 정방향 인덱스를 걸어도 페이지 간은 양방향으로 연결되어 있기 때문에 역순 정렬에 도움이 되지만, 페이지 내부의 실제 데이터끼리는 단방향으로만 연결되어 있기 때문에 DESC를 걸어줍니다.
장점
- 카디널리티가 낮은 컬럼이지만, 복합 인덱스로 사용되어 필터링에 효과적으로 활용됨
- 인덱스로 인해 정렬된 상태를 유지하므로 매 조회 시 발생하는 File Sort가 사라질 것으로 예상
단점
- 인덱스 용량이 커짐
- 쓰기 비용 발생
- 앞 필터링 조건에 변화는 적지만, 북마크 수가 변할 때마다 bookmark_count가 재정렬되어야 함
필터링 조건들은 미디어가 사용자에게 노출되기 위한 최소한의 조건으로, 삭제 여부/공개 여부/트랜스코딩 완료 여부를 확인합니다. 이는 User-API 서버에서 제공하는 미디어들에 대해 대부분 적용하고 있으므로, 인덱스의 사용 범위가 매우 넓어 활용도가 높습니다.
O+T 서비스에서 북마크는 보고 싶은 목록을 구성하는 일종의 모음 폴더 역할을 합니다. 따라서 북마크는 좋아요, 시청 등보다 훨씬 적게 발생할 것이므로 쓰기 빈도에 비해 조회 빈도가 매우 높아 인덱스 설정이 효과적일 것이라고 판단했습니다.
적용
코드 상 변경은 없었고, 인덱스 추가 flyway를 작성했습니다. 따라서 Where절의 모든 컬럼이 인덱스의 선행 컬럼에 해당되며, Order By의 bookmark_count가 후행 컬럼으로 인덱스를 타게 됩니다.
모든 조건 및 정렬이 인덱스를 활용하여 1323ms -> 68ms로 감소한 것을 확인할 수 있습니다.
INFO 38628 --- [io-8080-exec-10] p6spy: [STATEMENT] | 68 ms |
select
m1_0.id,
m1_0.bookmark_count,
...
where
m1_0.status='ACTIVE'
and m1_0.public_status='PUBLIC'
and m1_0.media_status='COMPLETED'
and m1_0.is_standalone=true
order by
m1_0.bookmark_count desc
...
개선 후 실행계획


테이블 풀 스캔 + Filesort에서 Index Condition(ICP)으로 변경되었으며, 전체적인 실행 시간도 매우 빨라졌습니다.
데이터 수와 환경에 따라 다르겠지만, 이렇게 가장 오래 걸렸던 첫 번째 쿼리가 3096ms -> 1323ms -> 68ms로 개선되었습니다.
2-2. 2번 쿼리: 3028ms
INFO 528 --- [io-8080-exec-10] p6spy : [STATEMENT] | 3028 ms |
select count(m1_0.id)
from media m1_0
where
m1_0.status='ACTIVE'
and (m1_0.public_status='PUBLIC'
and m1_0.media_status='COMPLETED')
and (m1_0.media_type='SERIES'
or m1_0.media_type='CONTENTS'
and not exists(select 1 from contents c1_0 where c1_0.media_id=m1_0.id and c1_0.series_id is not null))

두 번째 쿼리는
1. Where 절 or 조건 + 서브쿼리
2. count() 함수
로 인해 시간이 오래 걸립니다. 앞에서 서브쿼리와 조건절 및 정렬에 대한 인덱스를 설정했지만, count 쿼리 자체는 전체 개수를 세는 것이기 때문에 비교적 속도가 느렸습니다.
count 쿼리 발생 이유는 Page<T>를 반환하려면 총 데이터 수(totalElements) 가 필요한데, Spring Data의 Page 인터페이스가 getTotalPages(), getTotalElements()를 제공하기 때문에 Repository에서 데이터 쿼리와 별도로 동일 조건의 COUNT 쿼리를 한 번 더 날려야 했기 때문입니다.
전체 요소 개수가 필요 없다면, 그리고 Page 인터페이스 대신 Slice 인터페이스를 사용하면 count 쿼리가 발생하지 않기 때문에 쿼리 개선보다 코드 변경을 통해 쿼리 자체를 없애는 방법을 택했습니다.
또한, 해당 서비스는 번호가 있는 페이지네이션을 제공하는 것이 아닌, 특정 개수만큼만 무한 스크롤 형식으로 전달하면 됐기 때문에 Slice 인터페이스를 사용할 수 있었습니다.
| 필요한 정보 | Page | Slice |
| 현재 페이지 데이터 | O | O |
| 다음 페이지 존재 여부 | O (COUNT 기반) | O (limit+1 기반) |
| 총 페이지 수 | O | 불필요 |
| 총 데이터 수 | O | 불필요 |
코드 변경
boolean hasNext = content.size() > pageable.getPageSize();
if (hasNext) {
content = content.subList(0, pageable.getPageSize());
}
return new SliceImpl<>(content, pageable, hasNext);Page 대신 Slice로 변경하며, 전체 수가 아닌 다음 페이지가 존재하는지 확인한 후 구현체인 SliceImpl을 응답합니다.
이렇게 다른 플레이리스트는 페이지네이션이 필요한 경우 Page 인터페이스 대신 Slice를 사용할 수 있었고, 인기 차트 플레이리스트 API의 경우에는 페이지네이션이 필요하지 않으므로 List를 사용하여 상위 20개의 Media를 반환합니다.
2-3. N+1 쿼리
앞의 가장 큰 두 개의 쿼리 개선을 진행했음에도 한 번의 API 호출에 최대 60개의 N+1 쿼리가 발생하여 응답 시간이 여전히 300ms 근처에 머물렀습니다.
왜 발생하는가
Trending API는 인기 미디어 목록을 조회합니다. 이 목록에는 시리즈와 단편 콘텐츠가 섞여 있습니다.
단편 콘텐츠는 그 자체가 재생 대상이므로 추가 조회가 필요 없습니다. 하지만 시리즈는 껍데기입니다. 시리즈 자체를 재생할 수는 없고, 그 안의 에피소드 중 하나를 재생해야 합니다.
그래서 시리즈마다 아래 내용을 결정해야 합니다
- 이 유저가 가장 최근에 본 에피소드가 있으면 → 그 에피소드의 Media ID (이어보기)
- 시청 이력이 아예 없으면 → 1화의 Media ID (처음부터 보기)
이 결정을 for문 안에서 시리즈마다 개별 쿼리로 하고 있었습니다.
따라서 조회된 미디어가 시리즈일 경우 N+1 문제가 발생합니다. 아래 흐름으로 진행됩니다.
- 시리즈의 경우 이어보기 지점 표시를 위해 시리즈 내 미디어 중 가장 최근에 시청한 미디어를 찾아야 함
- Watch_History -> Contents -> Series -> Media
- 1번 쿼리에서 가져온 Media 개수 (20개)만큼 반복
기존 코드
for (Media media : mediaPage.getContent()) {
if (media.getMediaType() == MediaType.SERIES) {
// (1) 시리즈마다 시청 이력 조회 → 1회 쿼리
Long targetId = watchHistoryRepository
.findLatestContentMediaIdByMemberIdAndSeriesMediaId(memberId, media.getId())
// (2) 이력 없으면 1화 조회 → 2회 쿼리 (데이터 + COUNT)
.orElseGet(() -> getFirstEpisodeMediaId(media.getId()));
mediaToTargetIdMap.put(media.getId(), targetId);
} else {
mediaToTargetIdMap.put(media.getId(), media.getId());
}
}위 for문이 조회된 Media의 수만큼 반복되는 것이 문제였습니다. 한 페이지에 20개의 미디어가 있고 전부 시리즈라면 루프가 20번 돌면서 매번 DB에 쿼리를 날리게 됩니다.
최대 60개의 쿼리가 발생하는 이유
| 쿼리 | 발생 조건 | 횟수 |
| findLatestContentMediaIdByMemberIdAndSeriesMediaId | 시리즈마다 "이 유저가 최근에 본 에피소드가 있나?" 확인 : 시리즈마다 1회 |
20회 |
| getFirstEpisodeMediaId: 데이터 쿼리 | 시청 이력이 없으니 1화를 가져오러 감 : 시청 이력 없는 시리즈의 fallback |
20회 |
| getFirstEpisodeMediaId: Count 쿼리 | fallback이 Page 인터페이스를 반환하므로 COUNT가 따라옴 | 20회 |
| 합계 | 60회 |
getFirstEpisodeMediaId는 내부적으로 contentsRepository.findBySeries_Media_Id...를 호출하는데, 이 함수가 Page<Contents>를 반환합니다. Page는 totalElements를 알아야 하므로 데이터 쿼리와 별도로 COUNT 쿼리가 한 번 더 나갑니다. 그래서 시청 이력이 없는 시리즈 하나당 2회, 총 40회가 여기서 발생합니다.
정리하자면
본질적 원인: for문 안에서 시리즈마다 개별 쿼리를 날림
악화 요인: 1화 조회가 Page 반환이라 불필요한 COUNT 쿼리까지 추가 발생
문제
- 시리즈 20개면 최대 60번 쿼리 발생
- 각 1ms ~ 3ms로 괜찮아 보이지만, 클라우드에서 네트워크 지연이 누적될 수 있음
- 쿼리 수만큼 DB 커넥션을 점유하므로 동시 요청이 몰리면 커넥션 풀 소모가 빨라짐
해결: IN절 일괄 조회 ✅
시리즈 ID를 하나씩 불러오던 기존 방식에서 한 번에 불러오는 방식으로 변경하여 해당 문제를 해결하기로 했습니다.
구체적인 단계는 아래와 같습니다.
1단계. 시리즈 ID 목록 모으기
- for문에 들어가기 전에 조회된 미디어 중 시리즈만 골라서 ID 목록을 만듦
- 해당 목록이 IN절에 들어갈 값
2단계. 시청 이력 일괄 조회 (1회)
- 시리즈마다 1회씩 호출하던 기존 함수에서 목록을 한 번에 넘기는 함수로 교체하여 한 번에 조회
- Map<시리즈MediaId, 최근시청에피소드MediaId>를 반환
- 쿼리 내부에서는 서브쿼리로 시리즈별 MAX(lastWatchedAt)인 행을 찾아 해당 에피소드의 Media ID를 가져옴
3단계. 시청 이력 없는 시리즈 -> 1화 일괄 조회 (1회)
- 2단계에서 시청 이력이 없는 시리즈(latestEpisodeMap에 키가 없는 것)를 골라내어 이 시리즈들의 1화를 역시 IN절로 한 번에 조회
- 기존 getFirstEpisodeMediaId는 Page<Contents>를 반환해서 Count 쿼리가 발생했지만, 새 메서드는 Map<Long, Long>을 직접 반환하므로 Count 쿼리가 발생하지 않음
4단계. 두 맵을 합쳐 최종 결과 만들기
- 이 for문은 이미 조회된 Map에서 값을 꺼내기만 하므로 쿼리가 발생하지 않음
- 시청 이력이 있는 시리즈 → latestEpisodeMap에서 가져옴
- 시청 이력이 없는 시리즈 → firstEpisodeMap에서 가져옴
- 단편 콘텐츠 → 자기 자신의 ID
쿼리 수 비교
| 항목 | Before | After |
| 시청 이력 조회 | 시리즈 수 x 1회 (20회) | 1회 (IN절) |
| 1화 fallback 조회 | 이력 없는 시리즈 x2회 (40회) | 1회 (IN절, COUNT 없음) |
| 총 쿼리 수 | 최대 60회 | 2회 |
루프에서 하나하나 조회하는 것을 없애고, 미리 IN절로 한 번에 조회한 후 루프 안에서는 별도의 조회 없도록 변경하여 쿼리 수가 확연히 줄어들었습니다.
대안 비교
| 방법 | 설명 | 이 상황에 적합한지 |
| IN절 일괄 조회 | 시리즈 ID를 모아서 한 번에 조회 | 적합 - 조회 로직이 커스텀(최근 시청 에피소드)이라 직접 IN절로 제어해야 함 |
| @BatchSize | 지연 로딩 시 N개씩 묶어서 IN절 자동 생성 | 부적합 - JPA 연관관계 로딩용, 커스텀 비즈니스 쿼리에는 적용 불가 |
| @EntityGraph / Fetch Join | 연관관계를 즉시 로딩 | 부적합 - '시리즈 -> 최근 시청 에피소드'는 연관관계까 아닌 비즈니스 로직 기반 조회 |
이 경우 발생하는 많은 쿼리는 흔히 발생하는 JPA 지연 로딩으로 인한 N+1 문제와 달랐습니다. JPA로 인한 문제의 경우 주로 BatchSize나 Fetch Join 등으로 해결합니다. 하지만 이 경우의 N+1은 for문 안에서 커스텀 쿼리를 반복 호출하는 패턴입니다. '이 시리즈에서 이 유저가 가장 최근에 본 에피소드가 뭔지'는 엔티티 연관관계가 아니라 비즈니스 로직이므로, JPA 레벨의 자동 최적화가 적용되지 않습니다. 직접 IN절 쿼리를 작성하여 모아서 한 번에 쿼리를 날리는 방식으로 해결했습니다.
JPA로 인한 문제인지, 로직 상 쿼리 최적화가 가능한 부분인지를 먼저 살펴보고 그에 대한 적절한 해결책을 세우는 것이 중요했습니다.
3. 개선 결과
개선 전 Controller/Service 응답 시간
INFO 528 --- ... .PerformanceLoggingAspect: [SERVICE] PlaylistStrategyService.getPlaylists() 6457ms
INFO 528 --- ... .PerformanceLoggingAspect: [CONTROLLER] PlaylistController.getTrendingPlaylists() 6466ms개선 후 Controller/Service 응답 시간
INFO 37396 --- ... .PerformanceLoggingAspect: [SERVICE] PlaylistStrategyService.getPlaylists() 51ms :
INFO 37396 --- ... .PerformanceLoggingAspect: [CONTROLLER] PlaylistController.getTrendingPlaylists() 64ms
AOP로 Controller/Service 계층의 응답 시간을 비교해봤습니다. 대략 6400ms정도 걸리던 API 응답 시간이 작업 후 60~80ms 정도로 개선된 것을 확인할 수 있었습니다.
또한, 쿼리 수 자체도 64개 -> 5개로 최소화하여, 필요한만큼만 DB에 접근하게 되었습니다.
이렇게 쿼리 속도 개선과 쿼리 수 감소가 함께 어우러져 전체 API 응답 시간이 줄어들었습니다.
4. 캐싱 도입
4-1. 배경
홈 화면은 메인 페이지로, 서비스를 사용하는 모든 사용자가 처음 진입하는 가장 트래픽이 많은 지점입니다. 따라서 해당 페이지의 응답 속도가 곧 사용자 경험과 연결됩니다.

현재 조회 구조는 단순하게 Client 요청 -> Server -> DB 쿼리 순서로 진행됩니다. 매 요청마다 DB를 거칩니다.
여기서 DB 쿼리 횟수 자체를 줄인다면 트래픽이 늘어났을 때 응답 속도가 더욱 안정적일 것이라고 생각했고, 캐싱을 도입하기 위한 조건들을 검토해보았습니다.
인기 차트 API는 아래 특성들을 가지고 있습니다.
- 읽기 비중이 높고, 변경에 둔감하다.(약간의 지연 허용)
- 차트가 변하는 시점은 북마크 수가 변동될 때이고, 조회 대비 쓰기 비율이 낮다.
- 북마크 특성 상 쓰기 비중이 극히 낮진 않지만, 이를 인기 차트에 반영하는 것은 변경에 둔감하다. OTT 서비스에서는 오히려 실시간성을 위해 변경 사항을 즉시 반영하는 것보다 주기적으로 갱신하는 것이 좋다.(해당 프로젝트의 기획이기도 함)
- 모든 사용자가 동일한 데이터를 본다.
- 개인화가 없기 때문에 유저 A와 유저 B의 응답이 동일하다.
- 100명이 동시에 요청해도 DB에서 꺼내오는 결과는 하나이다.
- 쿼리 개선이 완료되었다.
- 앞의 과정을 거쳐 한 번의 요청에서 발생하는 쿼리 수를 줄이고, 속도를 개선했다.
- 남은 병목은 트래픽에 따른 DB 쿼리 횟수이다.
높은 읽기 비중 + 변경 지연 허용 + 모든 사용자에게 동일한 데이터 제공이라는 조건을 바탕으로 캐싱을 도입하면 응답 속도를 더욱 개선할 수 있다고 생각했습니다.
4-2. 인기 차트 플레이리스트 정의
캐싱 방식을 결정하기 전에 인기 차트 플레이리스트에 대한 기획 확정이 필요했습니다. 인기 차트 플레이리스트는 북마크 수가 가장 높은 Media 20개를 제공합니다.
1. 북마크 수 기반 인기 차트 실시간 반영 vs 지연 허용
또한, 데이터가 즉시 반영되어야 하는지에 따라 구조가 달라질 수 있습니다. 마찬가지로 DB 업데이트에 이어 캐시 데이터도 업데이트 하는지에 대한 문제가 발생하기 때문입니다.
현재 서비스의 인기 차트 플레이리스트는 북마크 수 기반으로 제공됩니다. 북마크는 사용자 행동으로 인해 발생하는 데이터로, 이 데이터가 발생할 때마다 실시간으로 반영해서 사용자에게 제공하는 방식과 일정 주기마다 데이터를 갱신해서 플레이리스트를 구성하는 방식이 있습니다.
넷플릭스나 왓챠같은 OTT 서비스들은 (북마크 기반같은 단순한 로직이 아니겠지만) 즉시 반영하기보다 일정 주기마다 순위를 갱신합니다. OTT 서비스의 특성을 고려했을 때, 실시간 반영보단 한 번에 뭉텅이로 제공하는 것이 더 낫다고 판단했습니다.
이렇게 된다면 DB와 캐시는 항상 일관된 데이터를 유지할 필요는 없습니다. DB를 중심으로 모든 데이터를 관리하고, 시간 단위로 데이터를 캐싱하는 방식을 사용할 수 있습니다.
따라서 '인기 차트 플레이리스트는 일정 시간의 지연을 허용한다'로 결정했습니다.
2. 데이터 불일치 가능 여부
다중 서버 환경에서는 캐시 데이터 불일치 문제가 발생할 수 있습니다.
홈 화면에서 새로고침을 할 때마다 인기 차트 플레이리스트가 변경된다면 사용자 입장에서 혼란을 겪을 수 있을 것이라고 생각했습니다. 물건의 수량이나 결제와 같이 완전무결하게 데이터가 유지되어야 하는 서비스는 아니지만, 사용자 경험 측면에서 살펴보면 일관된 데이터를 제공하는 것이 좋습니다.
따라서 데이터 일치에 관해서 '사용자는 일관된 데이터를 받아야 한다'로 결정했습니다.
4-3. 캐싱 방식 결정
1. 로컬 캐시 단독 사용
각 서버마다 로컬 캐시를 두고, 요청 시 각자의 캐시에서 데이터를 확인하고 응답하는 방식입니다.
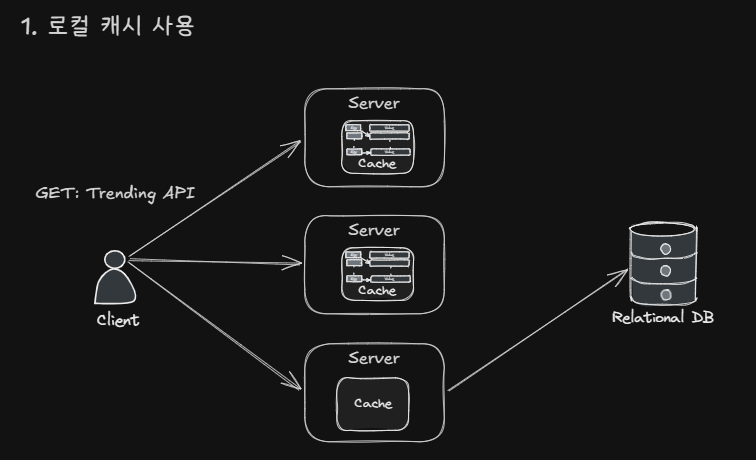
가장 큰 장점은 응답속도가 빠릅니다. 네트워크 지연 없이 각 서버의 메모리에서 바로 응답하기 때문입니다.
하지만, TTL 범위 내에서 일관된 데이터를 응답하지 않을 수 있습니다. 서버 1의 TTL이 먼저 만료되어 새로운 데이터를 가져오고, 서버 2는 아직 이전 데이터를 가지고 있을 때 응답 데이터의 차이가 나타납니다. 또한, Auto Scaling에 따라 새로운 서버 인스턴스가 생성되고, 캐시 데이터 구성 시 다른 서버들과 다른 데이터를 가지고 있을 수도 있습니다.
앞서 정의한 내용에 따르면 '데이터 불일치'를 허용하지 않았기 때문에 이러한 요구사항에서는 추가적인 갱신 방법을 도입하지 않는다면 사용하기 어려운 방식입니다.
2. 글로벌 캐시 사용 ✅
각 서버별 캐시가 아닌 Redis 혹은 Memcached와 같은 글로벌 캐시를 두어 요청이 올 때마다 모든 서버가 해당 캐시를 보고 데이터를 응답하는 방식입니다.

첫 번째 방식인 로컬 캐시에 비해 응답 속도는 느리지만, DB에 직접 접근하여 쿼리를 날리지 않고, 이미 가공된 데이터가 글로벌 캐시에 존재하기 때문에 충분히 응답 속도가 빠릅니다. 이 방식은 캐시 자체가 글로벌 캐시 하나만 존재하기 때문에 서버 캐시 간 데이터 불일치 문제가 해결됩니다.
단점은 운영 복잡도가 올라간다는 것입니다. 인프라 하나가 추가되기 때문입니다. 또한, 해당 글로벌 캐시가 SPOF가 된다는 점입니다. 모든 서버가 하나의 캐시를 보기 때문에 해당 서버의 장애 발생 시 모든 서버의 캐시가 동시에 사라지고, 전체 트래픽이 DB로 직행합니다.
3. 로컬 캐시 + Redis Pub/Sub
1번 방법처럼 각 인스턴스가 로컬 캐시를 유지하되, 데이터 변경 시 Redis Pub/Sub과 같은 메시징 시스템을 사용하여 모든 인스턴스에 캐시 무효화 이벤트를 발행하여 캐시를 동기화하는 방식입니다.

첫 번째 방법의 가장 큰 문제였던 데이터 일관성 문제가 개선됩니다. 변경이 발생하면 모든 인스턴스가 거의 동시에 캐시를 갱신하므로 인스턴스 간 차이가 최소화됩니다. 조회 시에는 로컬 캐시를 사용하므로 글로벌 캐시로의 네트워크 비용조차 아껴야 하는 트래픽이 쏟아지며 조회가 매우 빈번하게 발생하는 상황에서 유용하게 쓰입니다.
단점은 로컬 캐시를 사용함에도 Redis 의존성, 메시지 유실/중복 처리, Pub/Sub 구독 관리와 같은 복잡도가 높아진다는 것입니다. 또한, 일시적으로 구독이 끊기는 등 장애 상황에서의 대비로 캐시의 TTL 설정 또한 필요합니다.
해당 프로젝트는 앞서 정의한 것처럼 북마크 수의 '실시간 반영'이 필요하지 않고, 주기적인 갱신이 필요합니다. 따라서 사용자의 북마크 혹은 북마크 취소로 인한 랭킹 변동을 캐시 데이터에 즉 반영할 필요가 없습니다. 사실상 TTL 만료 시에만 메시지가 발행됩니다. 이렇게 매우 드물게 발생하는 작업을 위해 새로운 인프라를 추가하고, 관리 포인트를 늘리는 것이 부담될 수 있습니다.
네트워크 지연을 최소화하거나 Redis나 다른 메시징 시스템 등 이미 사용 중인 인프라가 존재하는 경우에는 충분히 고려할 만한 선택지라고 생각합니다.
4. 로컬 캐시 (L1) + 글로벌 캐시 (L2)
각 서버에 로컬 캐시를 두고, 모든 서버가 사용하는 글로벌 캐시도 두는 방식입니다. 요청이 들어오면 먼저 로컬 캐시(L1)를 확인하고, 미스 시 Redis(L2)를 조회하고, 그것도 미스면 DB를 조회하는 계층 구조입니다.
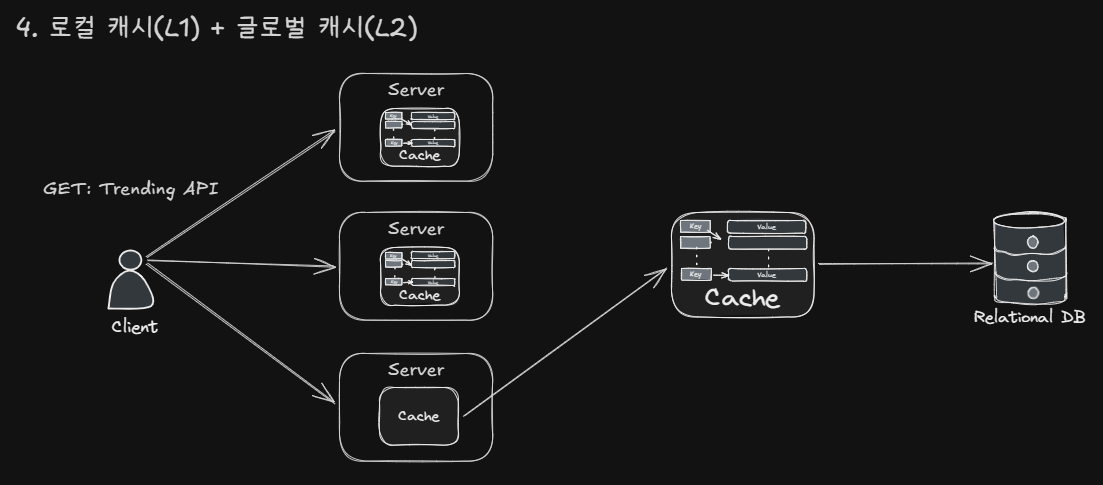
로컬 캐시의 속도와 글로벌 캐시의 일관성을 동시에 얻을 수 있습니다. L1 TTL을 짧게(ex. 1분), L2 TTL을 길게(ex. 5분) 설정하면 대부분의 요청은 L1에서 처리되고, L1 미스 시에도 DB까지 가지 않고 L2에서 응답합니다.
하지만 해당 API에서는 복잡도 대비 이점이 적습니다. TTL 내 적중률이 높은 상황에서 L1 미스가 발생하는 시점은 TTL 만료 직후뿐입니다. 이때 DB를 한 번 조회하는 것과 Redis를 한 번 조회하는 것의 차이는 미미합니다. 앞선 쿼리 개선 작업 이후 쿼리 자체가 큰 병목이 아닌 상황에서 L2 계층이 막아주는 DB 부하가 크지 않습니다.
결국, L1 TTL 관리, L2 TTL 관리, 계층 간 정합성, Redis 의존성까지 모두 안고 가면서 얻는 실질적 이점이 부족해 보입니다.
정리
| 방안 | 응답 속도 | 일관성 | 복잡도 |
| 로컬 캐시 단독 | 매우 빠름 | TTL 내 불일치 | 최소 |
| 글로벌 캐시 단독 | 빠름 | 거의 일치 | 중간 |
| 로컬 캐시 + Redis Pub/Sub | 매우 빠름 | 완전 일치 | 높음 |
| L1 + L2 계층 | 빠름(TTL 짧음) | TTL 내 불일치 | 높음 |
팀에서는 데이터 일관성과 구현 및 관리 복잡도를 고려하여 글로벌 캐시와 로컬 캐시 + Redis Pub/Sub 중 고민하다가 글로벌 캐시를 사용하기로 결정했습니다.
로컬 캐시를 활용하는 방안을 여러 방면으로 고려해봤지만, 데이터 일치 문제와 이를 해결하기 위한 메시징 시스템은 오히려 과하다고 생각했습니다.
4-4. Memcached vs Redis
글로벌 캐시에 대표적으로 사용되는 Memcached와 Redis 두 가지를 검토했습니다.
Memcached는 단순한 Key-Value 인메모리 캐시입니다. 멀티스레드 기반으로 동작하며, 단순 캐싱 용도에 매우 빠르고 가볍습니다. 하지만, 자료구조가 단순 Key-Value뿐이며 영속성 기능이 존재하지 않는 등 부가적인 기능이 적습니다.
Redis는 다양한 자료구조를 지원하는 인메모리 데이터 스토어입니다. 캐시 외에도 다양한 용도로 사용 가능합니다. 풍부한 자료구조 (String, List, Set, Sorted Set, Hash ...)를 제공하며, 영속성 옵션 (AOF) 또한 존재합니다. 하지만, memcached보다 복잡도가 높다는 점도 존재합니다.
선택: Redis
Redis를 사용하기로 결정했고, 아래의 이유들을 고민했습니다.
- 확장 가능성: 현재는 단순 Key-Value 캐싱이지만, 다른 기능에서 Redis를 재사용할 가능성이 높습니다. 또한, 차후 차트 정렬을 Redis 자체에 맡기는 방식(Sorted Set)으로 전환하거나 시간 윈도우 trending을 도입할 경우 Redis의 다양한 자료구조가 적합하기 때문입니다.
- 학습: Spring Data Redis, Redisson, RedisTemplate 등 생태계가 풍부하고 학습 자료가 많습니다.
4-5. String vs Sorted Set(ZSET)
String 타입은 20개의 인기 차트에 대한 응답을 JSON 직렬화된 형태로 통째로 저장합니다.
미디어 플레이리스트는 응답은 ID만 필요한 게 아니라 제목, 썸네일 등 메타데이터까지 포함됩니다. JSON 형식으로 데이터를 통째로 캐싱하여 그대로 응답할 수 있어, 추가적인 DB 조회가 필요없습니다. 또한, GET/SET 두 가지 명령어를 사용하며 구현이 매우 단순합니다.
Sorted Set은 score로 정렬된 member들의 집합입니다. Media ID를 식별자로 미디어별 score를 기준으로 정렬된 형태를 유지합니다.
부분 갱신, 페이지네이션, score 범위 조회와 같은 ZSET 기능이 필요하지 않음
- 배치로 TOP 20을 통째 갱신 / 한 콘텐츠만 score 바꾸는 시나리오
- 인기 차트는 TOP 20 고정 노출 -> 11~20위 별도 페이지 x
- score 범위 조회 불필요 -> '북마크 5000개 이상인 콘텐츠' 등 x
메타데이터 분리 운영
- ZSET에는 contentId만 저장되므로 제목, 썸네일 등의 메타데이터는 별도 캐싱하거나 DB 조회 필요
ZSET의 강점이 활용되지 않음
- 자동 정렬은 좋지만, IN절은 순서를 보장하지 않으므로 추려진 데이터에 대해 DB에서 정렬 후 가져옴
이러한 이유로 String 타입에 JSON 형식으로 응답 페이로드를 모두 캐싱하기로 결정했습니다. 인기 차트 플레이리스트는 20개 뿐이며, 필요한 컬럼만 추려서 저장한다면 메모리에 큰 부담이 없을 것이라고 생각했습니다.
하지만, 실시간성이나 정교한 요청 등 결국 확장을 생각하면 ZSET을 고려하는 것이 좋을 것 같습니다.
4-6. 캐싱 전략
Cache Aside + Write Around
읽기 전략은 Cache Aside, 쓰기 전략은 Write Around를 선택했습니다.

그림처럼 사용자의 요청이 들어오면 바로 DB를 보는 것이 아닌 캐시를 먼저 확인합니다. 캐시에 데이터가 존재하면 바로 응답을 보내고, 그렇지 않다면 DB에서 데이터를 조회한 후 캐시에 저장하고, 사용자에게 응답 데이터를 보냅니다.
사용자의 북마크 설정 및 취소 행동이 발생하면 쓰기 작업이 시작됩니다. 앞서 일정 주기 간격으로 랭킹을 갱신하기로 결정했으므로 쓰기 작업을 바로 캐시에 반영하지 않고, RDB에만 반영합니다. 그리고 설정해 둔 캐시 데이터의 TTL이 만료되면 DB에서 새로운 랭킹을 받아 저장합니다.
TTL
TTL은 1시간으로 잡았습니다. 넷플릭스의 인기 순위를 살펴봐도 그 주기가 더 긴 것 같지만, 해당 프로젝트는 복합적인 요소가 아닌 북마크 수 기반이므로 너무 길게 잡지 않고 적당한 주기로 갱신하기로 결정했습니다.
적용
Spring의 @Cacheable을 Service 계층에 붙여주어 간단히 적용할 수 있었습니다.
@Cacheable(value = "trending", key = "#top20")
public TrendingPlaylistResponse getTrending() {
// 북마크 수 Top 20 조회
}
캐시 스탬피드 문제
TTL 만료 시점에 동시에 여러 트래픽이 발생하는 경우 순간적으로 DB에 부하가 크게 발생할 수 있습니다. 쿼리 개선 후 진행되고 있고, 캐시를 사용하는 지점도 많지 않아 현재는 크게 문제가 되지 않지만, 캐시를 사용하는 부분이 많아진다면 응답 지연의 원인이 될 수 있습니다.
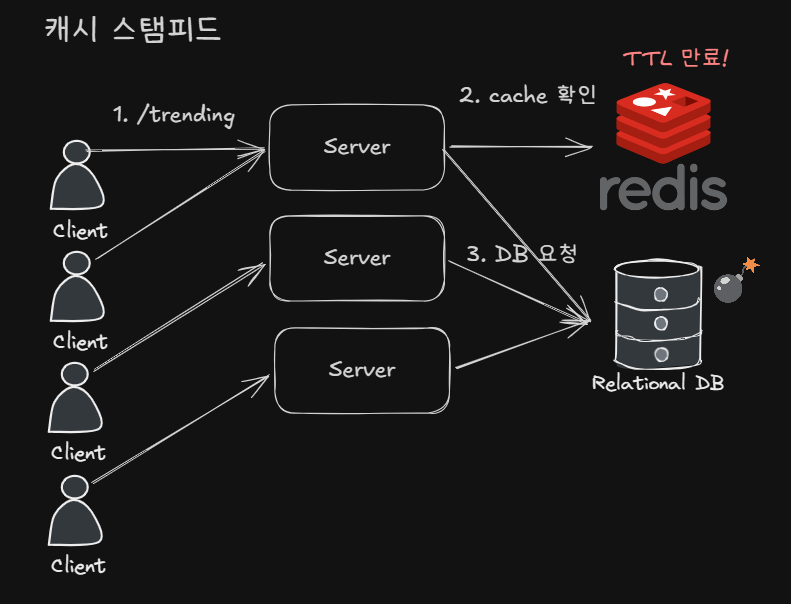
해결에는 Lock, PER, 논리적 만료 + 비동기 갱신, pre-warming 등 여러 방법이 존재합니다. 저는 간단하게 스케줄러를 통해 TTL보다 아주 약간 짧은 주기로 데이터를 갱신하도록 구성했습니다.
이 경우에는 다중 서버에서 스케줄러가 여러 번 실행되어 중복 갱신이 될 수 있으므로 ShedLock이나 분산 락으로 한 번만 실행되게 설정해줍니다.
5. 결과
캐시 히트 시 레디스에서 바로 꺼내오기 때문에 응답시간이 굉장히 빨라진 것을 확인할 수 있었습니다.
INFO 37396 --- ... .PerformanceLoggingAspect: [CONTROLLER] PlaylistController.getTrendingPlaylists() 4ms
시작 전과 동일한 VU 구성으로 부하 테스트를 해 봤습니다. 데이터 셋은 Large -> XLarge로 변해 개선 후가 훨씬 데이터가 많음에도 응답 속도가 빨라진 것을 확인할 수 있었습니다.

6. 마무리
다중 서버라고 무작정 인프라를 추가하는 방식보다 최대한 각 인스턴스의 로컬 자원을 활용할 수 있는 방법을 고민해봤습니다. 하나의 서버에서 사용할 수 있는 것을 최대한 사용하는 것이 좋다고 생각했습니다. 결국은 트래픽에 따라 조정할 일이고, 무언가 추가된다면 그에 따른 운영 비용이 발생할 수 있음을 체감했습니다.
기획적으로 결정된 사항에 알맞게 해결 방식을 결정하는 것도 중요했습니다. 프로젝트에서 기능을 구현하면서 시리즈/콘텐츠 쪽에 시간을 많이 사용했고, '인기 차트'를 정의하면서도 나름대로의 기준이 필요했습니다. 기획/설계 단계에서 실시간성이 짙은 인기 차트를 제공하고자 한다면 Redis의 자료구조 중 하나인 ZSET을 사용할 수도 있다는 말이 나왔던 기억이 있습니다. 기획이 모호하면 기술 결정에 어려움이 있을 것이라는 점을 다시 한 번 떠올렸습니다.
이번 개선 작업은 눈으로 확인할 수 있는 정보를 바탕으로 여러 대안을 하나씩 따져가며 진행했습니다. 마무리 단계에서 돌아보면 간단한 개선 작업이었지만, 선택한 방식 외에도 다른 방식들을 살펴볼 수 있었고, 그들보다 현재 방식을 선택한 이유를 찾고자 고민했기 때문에 생각보다 시간을 많이 사용한 것 같습니다.
'Project' 카테고리의 다른 글
| [O+T] 영상 품질 기반 개선기 (2. Per-Title-Encoding) (0) | 2026.06.26 |
|---|---|
| [O+T] 영상 이어보기 처리량 개선하기 (0) | 2026.05.13 |
| [O+T] 테스트 준비하기 (2) | 2026.04.28 |
| 다중 기기 환경에서의 푸시 알림 (0) | 2025.04.03 |
| 상황별 조회수 성능을 위해 고려할 수 있는 것 (0) | 2025.04.01 |